 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceExtender: Short-utterance Text-independent Speaker Verification with Guided Diffusion Model
Paper and Code
Oct 07, 2023
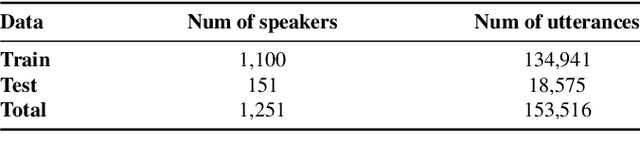
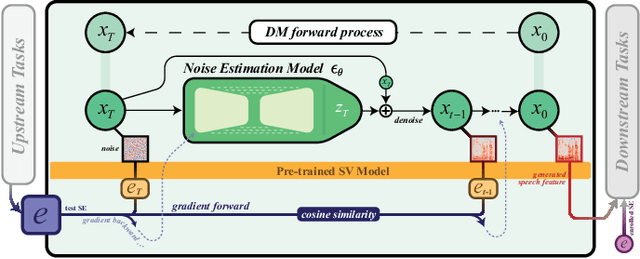
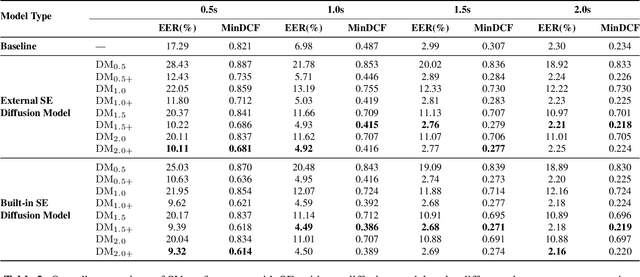
Speaker verification (SV) performance deteriorates as utterances become shorter. To this end, we propose a new architecture called VoiceExtender which provides a promising solution for improving SV performance when handling short-duration speech signals. We use two guided diffusion models, the built-in and the external speaker embedding (SE) guided diffusion model, both of which utilize a diffusion model-based sample generator that leverages SE guidance to augment the speech features based on a short utterance. Extensive experimental results on the VoxCeleb1 dataset show that our method outperforms the baseline, with relative improvements in equal error rate (EER) of 46.1%, 35.7%, 10.4%, and 5.7% for the short utterance conditions of 0.5, 1.0, 1.5, and 2.0 seconds, respectively.