 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVM-Net: Mesh Modeling to Assist Segmentation in Volumetric Data
Paper and Code
Dec 08, 2019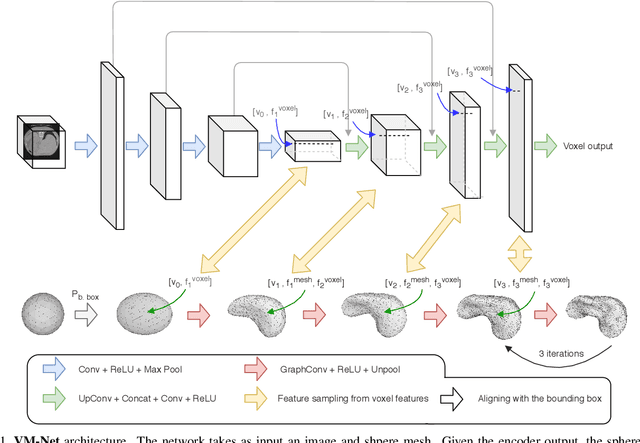
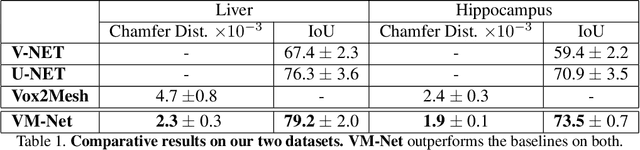
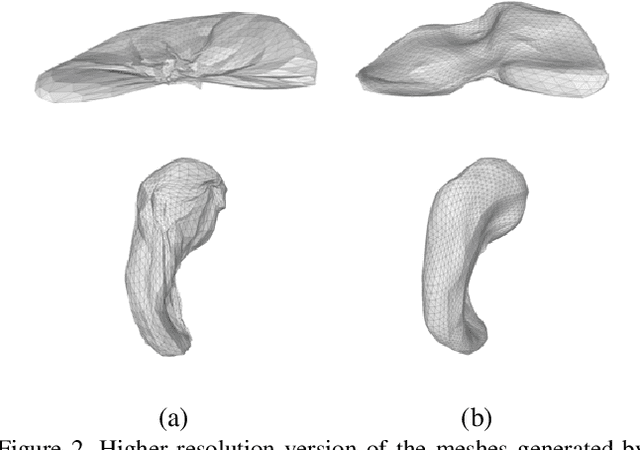
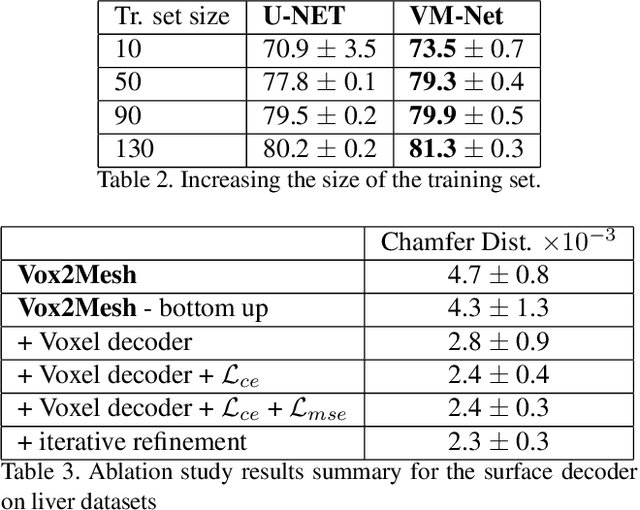
CNN-based volumetric methods that label individual voxels now dominate the field of biomedical segmentation. In this paper, we show that simultaneously performing the segmentation and recovering a 3D mesh that models the surface can boost performance. To this end, we propose an end-to-end trainable two-stream encoder/decoder architecture. It comprises a single encoder and two decoders, one that labels voxels and the other outputs the mesh. The key to success is that the two decoders communicate with each other and help each other learn. This goes beyond the well-known fact that training a deep network to perform two different tasks improves its performance. We will demonstrate substantial performance increases on two very different and challenging datasets.