 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLocNet++: Deep Multitask Learning for Semantic Visual Localization and Odometry
Paper and Code
Oct 11, 2018


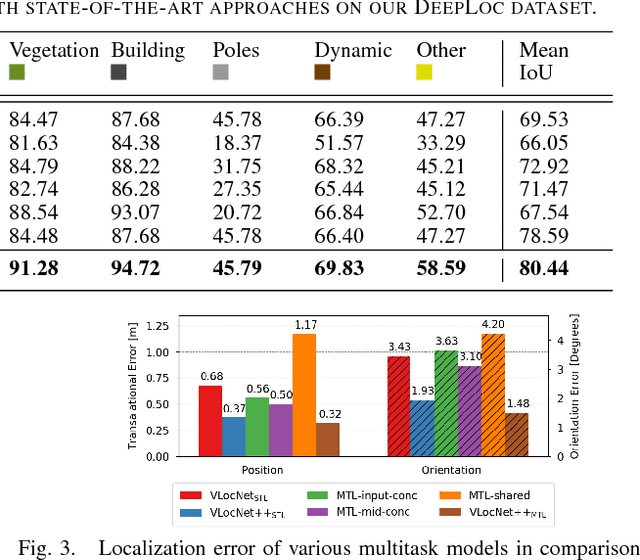
Semantic understanding and localization are fundamental enablers of robot autonomy that have for the most part been tackled as disjoint problems. While deep learning has enabled recent breakthroughs across a wide spectrum of scene understanding tasks, its applicability to state estimation tasks has been limited due to the direct formulation that renders it incapable of encoding scene-specific constrains. In this work, we propose the VLocNet++ architecture that employs a multitask learning approach to exploit the inter-task relationship between learning semantics, regressing 6-DoF global pose and odometry, for the mutual benefit of each of these tasks. Our network overcomes the aforementioned limitation by simultaneously embedding geometric and semantic knowledge of the world into the pose regression network. We propose a novel adaptive weighted fusion layer to aggregate motion-specific temporal information and to fuse semantic features into the localization stream based on region activations. Furthermore, we propose a self-supervised warping technique that uses the relative motion to warp intermediate network representations in the segmentation stream for learning consistent semantics. Finally, we introduce a first-of-a-kind urban outdoor localization dataset with pixel-level semantic labels and multiple loops for training deep networks. Extensive experiments on the challenging Microsoft 7-Scenes benchmark and our DeepLoc dataset demonstrate that our approach exceeds the state-of-the-art outperforming local feature-based methods while simultaneously performing multiple tasks and exhibiting substantial robustness in challenging scenarios.