 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
Paper and Code
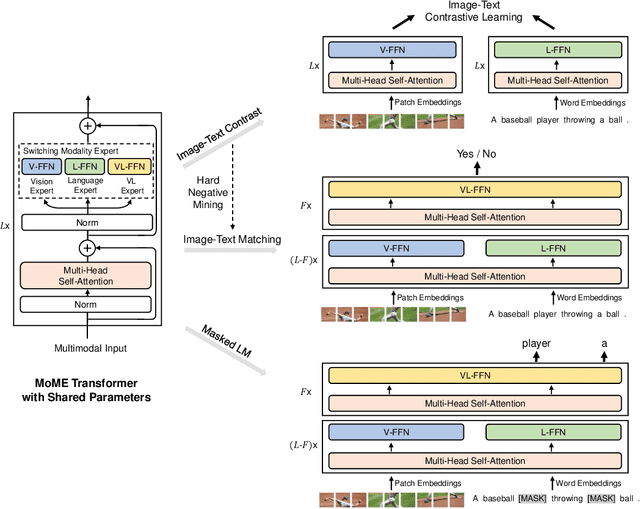
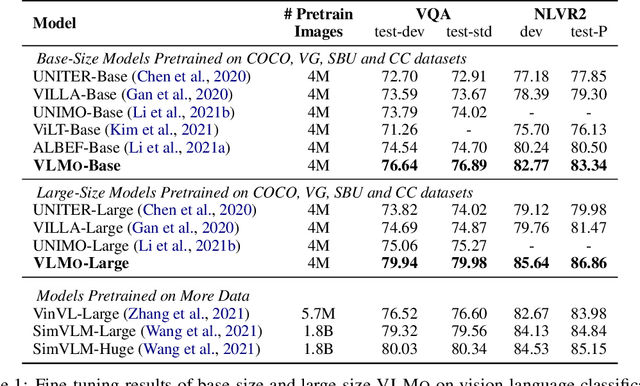


We present a unified Vision-Language pretrained Model (VLMo) that jointly learns a dual encoder and a fusion encoder with a modular Transformer network. Specifically, we introduce Mixture-of-Modality-Experts (MoME) Transformer, where each block contains a pool of modality-specific experts and a shared self-attention layer. Because of the modeling flexibility of MoME, pretrained VLMo can be fine-tuned as a fusion encoder for vision-language classification tasks, or used as a dual encoder for efficient image-text retrieval. Moreover, we propose a stagewise pre-training strategy, which effectively leverages large-scale image-only and text-only data besides image-text pairs. Experimental results show that VLMo achieves state-of-the-art results on various vision-language tasks, including VQA and NLVR2. The code and pretrained models are available at https://aka.ms/vlmo.