 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition
Paper and Code

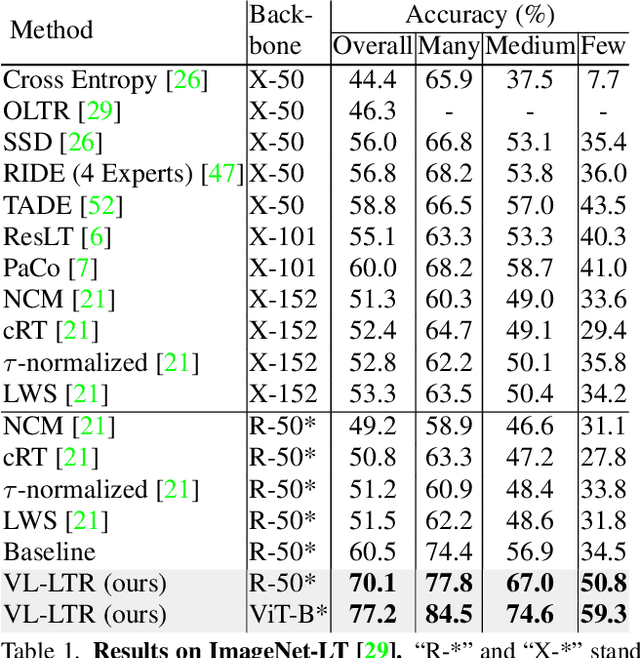

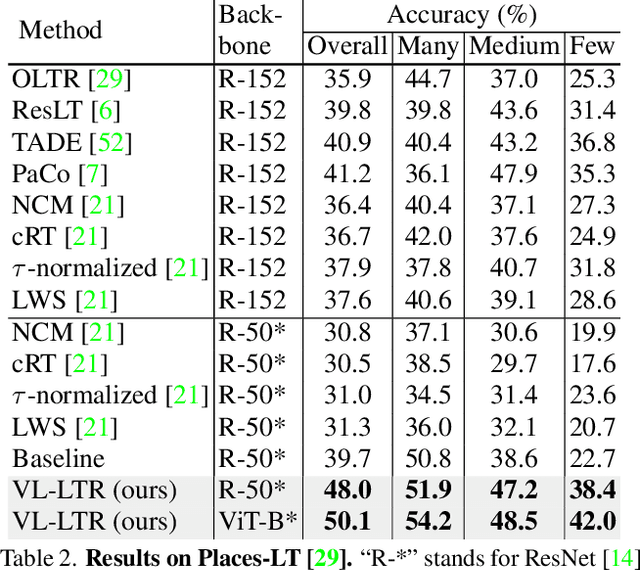
Deep learning-based models encounter challenges when processing long-tailed data in the real world. Existing solutions usually employ some balancing strategies or transfer learning to deal with the class imbalance problem, based on the image modality. In this work, we present a visual-linguistic long-tailed recognition framework, termed VL-LTR, and conduct empirical studies on the benefits of introducing text modality for long-tailed recognition (LTR). Compared to existing approaches, the proposed VL-LTR has the following merits. (1) Our method can not only learn visual representation from images but also learn corresponding linguistic representation from noisy class-level text descriptions collected from the Internet; (2) Our method can effectively use the learned visual-linguistic representation to improve the visual recognition performance, especially for classes with fewer image samples. We also conduct extensive experiments and set the new state-of-the-art performance on widely-used LTR benchmarks. Notably, our method achieves 77.2% overall accuracy on ImageNet-LT, which significantly outperforms the previous best method by over 17 points, and is close to the prevailing performance training on the full ImageNet. Code shall be released.