 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-CAT: Parallel Vision Transformers with Cross Attention Fusion for Popularity Prediction in MEC Networks
Paper and Code
Oct 27, 2022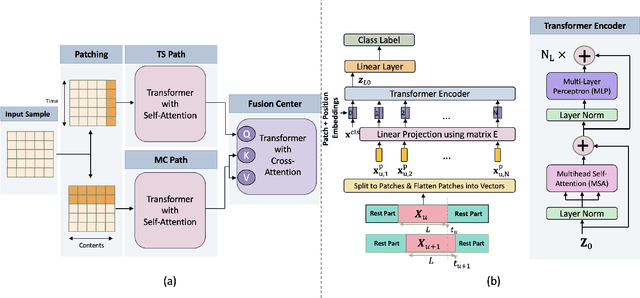
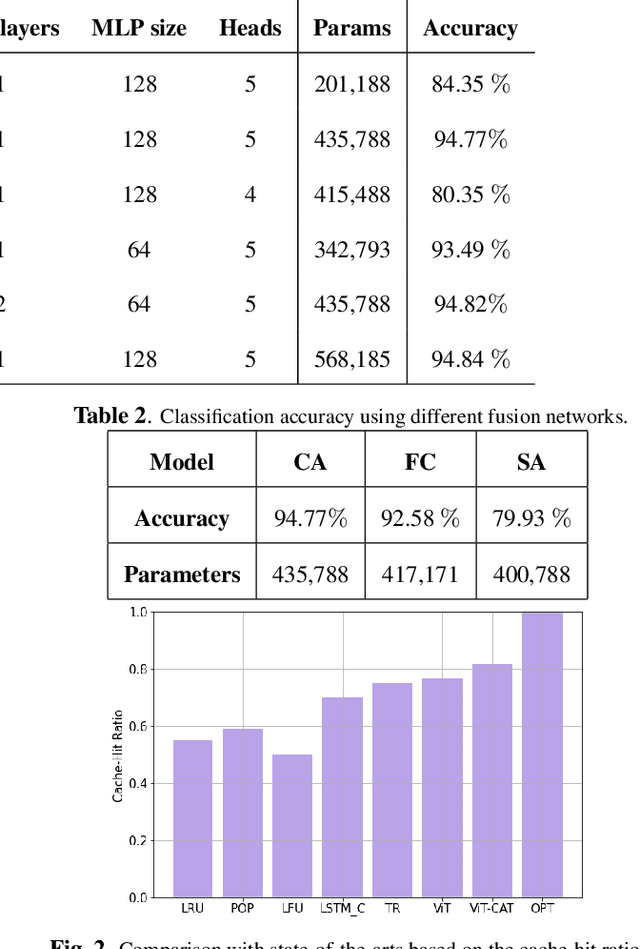
Mobile Edge Caching (MEC) is a revolutionary technology for the Sixth Generation (6G) of wireless networks with the promise to significantly reduce users' latency via offering storage capacities at the edge of the network. The efficiency of the MEC network, however, critically depends on its ability to dynamically predict/update the storage of caching nodes with the top-K popular contents. Conventional statistical caching schemes are not robust to the time-variant nature of the underlying pattern of content requests, resulting in a surge of interest in using Deep Neural Networks (DNNs) for time-series popularity prediction in MEC networks. However, existing DNN models within the context of MEC fail to simultaneously capture both temporal correlations of historical request patterns and the dependencies between multiple contents. This necessitates an urgent quest to develop and design a new and innovative popularity prediction architecture to tackle this critical challenge. The paper addresses this gap by proposing a novel hybrid caching framework based on the attention mechanism. Referred to as the parallel Vision Transformers with Cross Attention (ViT-CAT) Fusion, the proposed architecture consists of two parallel ViT networks, one for collecting temporal correlation, and the other for capturing dependencies between different contents. Followed by a Cross Attention (CA) module as the Fusion Center (FC), the proposed ViT-CAT is capable of learning the mutual information between temporal and spatial correlations, as well, resulting in improving the classification accuracy, and decreasing the model's complexity about 8 times. Based on the simulation results, the proposed ViT-CAT architecture outperforms its counterparts across the classification accuracy, complexity, and cache-hit ratio.