 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing classification results
Paper and Code
Jul 28, 2020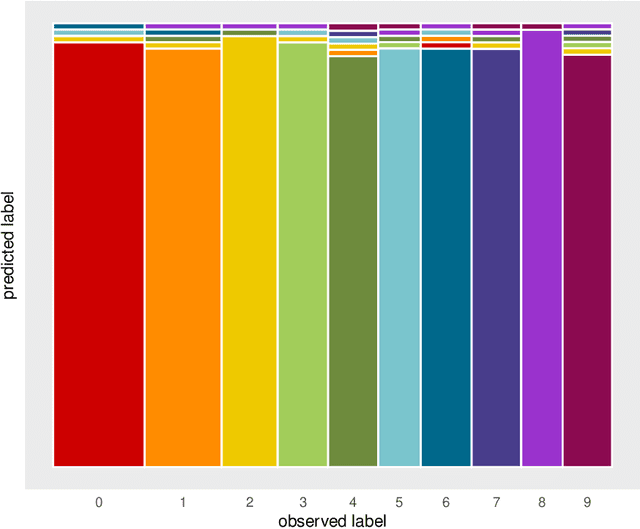

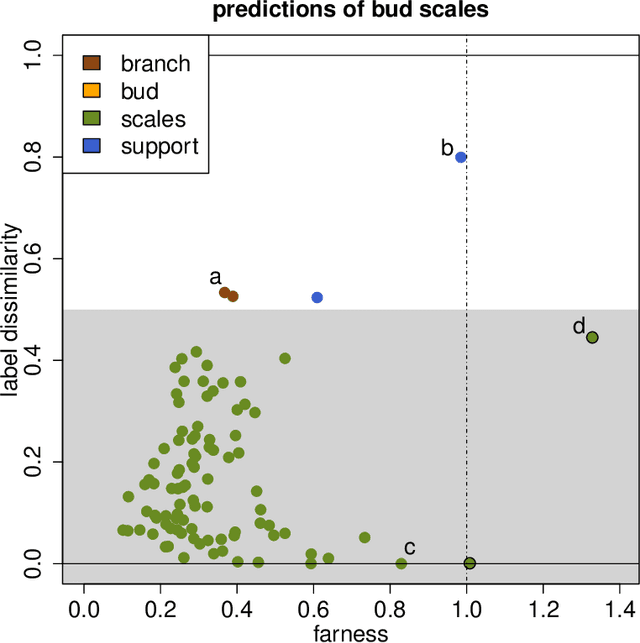

Classification is a major tool of statistics and machine learning. A classification method first processes a training set of objects with given classes (labels), with the goal of afterward assigning new objects to one of these classes. When running the resulting prediction method on the training data or on test data, it can happen that an object is predicted to lie in a class that differs from its given label. This is sometimes called label bias, and raises the question whether the object was mislabeled.Our goal is to visualize aspects of the data classification to obtain insight. The proposed display reflects to what extent each object's label is (dis)similar to its prediction, how far each object lies from the other objects in its class, and whether some objects lie far from all classes. The display is constructed for discriminant analysis, the k-nearest neighbor classifier, support vector machines, logistic regression, and majority voting. It is illustrated on several benchmark datasets containing images and texts.