 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Perception Generalization for Vision-and-Language Navigation via Meta-Learning
Paper and Code
Jan 19, 2021
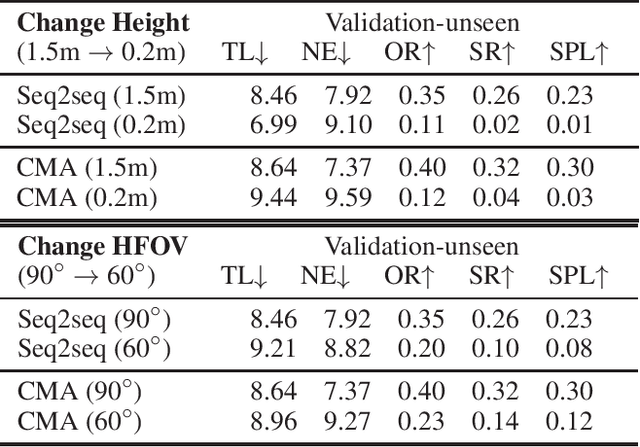
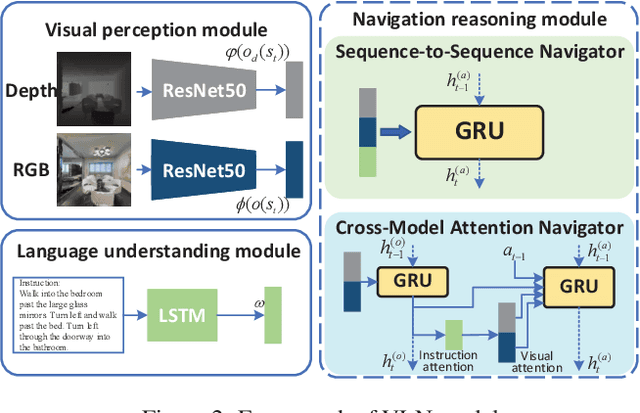
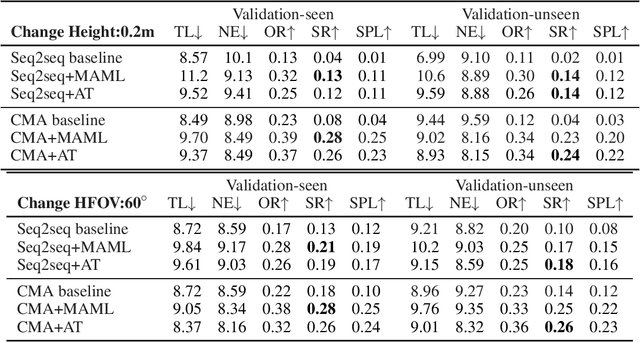
Vision-and-language navigation (VLN) is a challenging task that requires an agent to navigate in real-world environments by understanding natural language instructions and visual information received in real-time. Prior works have implemented VLN tasks on continuous environments or physical robots, all of which use a fixed camera configuration due to the limitations of datasets, such as 1.5 meters height, 90 degrees horizontal field of view (HFOV), etc. However, real-life robots with different purposes have multiple camera configurations, and the huge gap in visual information makes it difficult to directly transfer the learned navigation model between various robots. In this paper, we propose a visual perception generalization strategy based on meta-learning, which enables the agent to fast adapt to a new camera configuration with a few shots. In the training phase, we first locate the generalization problem to the visual perception module, and then compare two meta-learning algorithms for better generalization in seen and unseen environments. One of them uses the Model-Agnostic Meta-Learning (MAML) algorithm that requires a few shot adaptation, and the other refers to a metric-based meta-learning method with a feature-wise affine transformation layer. The experiment results show that our strategy successfully adapts the learned navigation model to a new camera configuration, and the two algorithms show their advantages in seen and unseen environments respectively.