 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual interpretation of the robustness of Non-Negative Associative Gradient Projection Points over function minimizers in mini-batch sampled loss functions
Paper and Code
Mar 20, 2019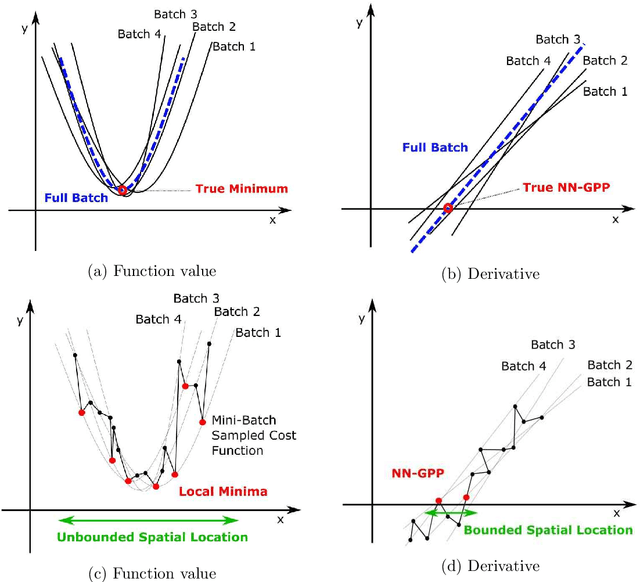
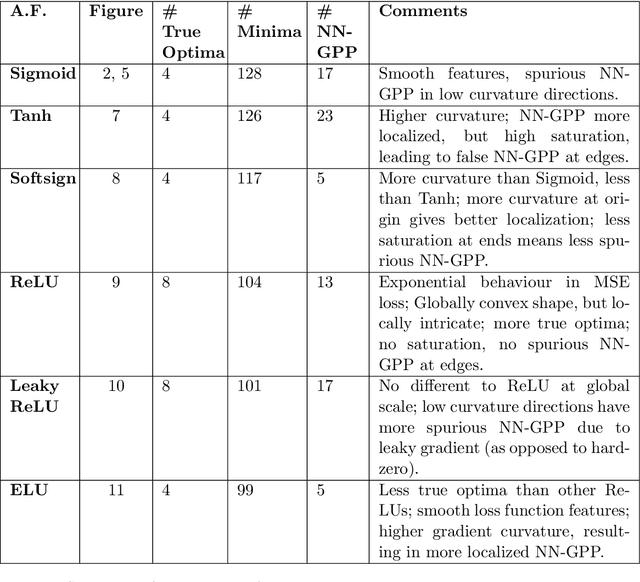
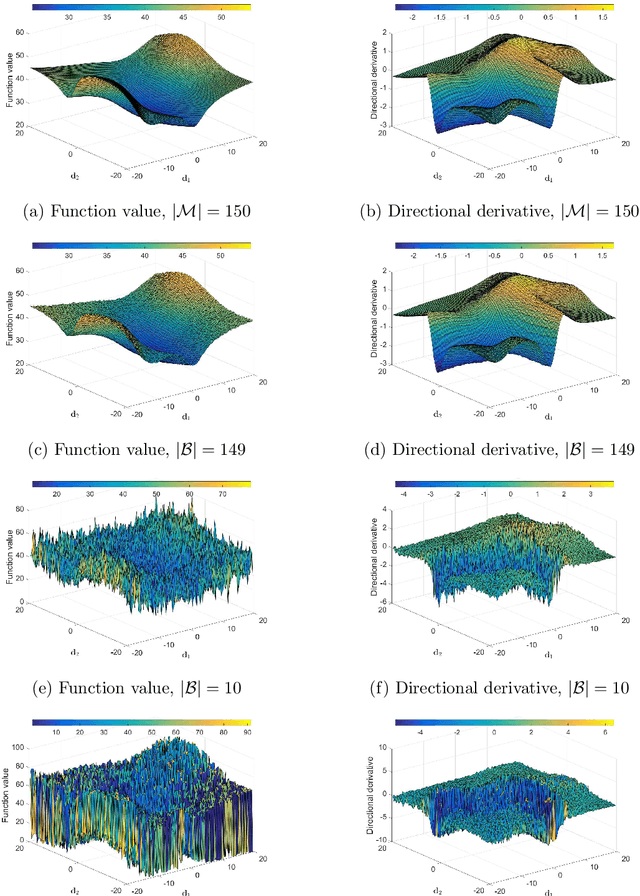
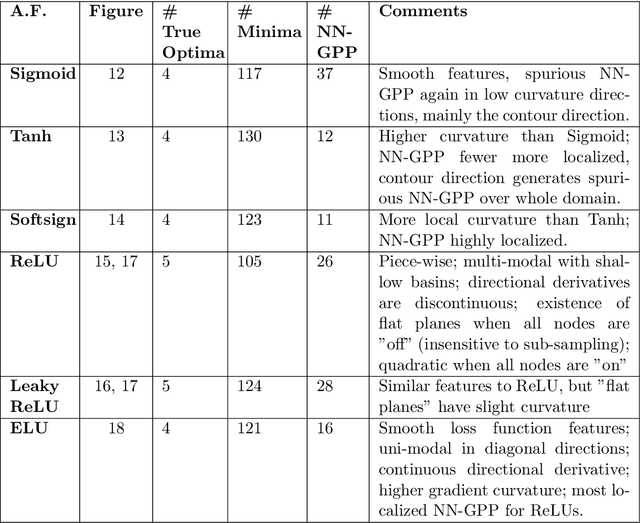
Mini-batch sub-sampling is likely here to stay, due to growing data demands, memory-limited computational resources such as graphical processing units (GPUs), and the dynamics of on-line learning. Sampling a new mini-batch at every loss evaluation brings a number of benefits, but also one significant drawback: The loss function becomes discontinuous. These discontinuities are generally not problematic when using fixed learning rates or learning rate schedules typical of subgradient methods. However, they hinder attempts to directly minimize the loss function by solving for critical points, since function minimizers find spurious minima induced by discontinuities, while critical points may not even exist. Therefore, finding function minimizers and critical points in stochastic optimization is ineffective. As a result, attention has been given to reducing the effect of these discontinuities by means such as gradient averaging or adaptive and dynamic sampling. This paper offers an alternative paradigm: Recasting the optimization problem to rather find Non-Negative Associated Gradient Projection Points (NN-GPPs). In this paper, we demonstrate the NN-GPP interpretation of gradient information is more robust than critical points or minimizers, being less susceptible to sub-sampling induced variance and eliminating spurious function minimizers. We conduct a visual investigation, where we compare function value and gradient information for a variety of popular activation functions as applied to a simple neural network training problem. Based on the improved description offered by NN-GPPs over minimizers to identify true optima, in particular when using smooth activation functions with high curvature characteristics, we postulate that locating NN-GPPs can contribute significantly to automating neural network training.