 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Context-driven Audio Feature Enhancement for Robust End-to-End Audio-Visual Speech Recognition
Paper and Code
Jul 13, 2022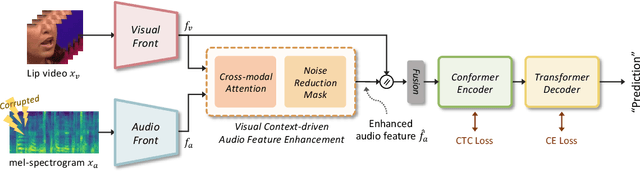
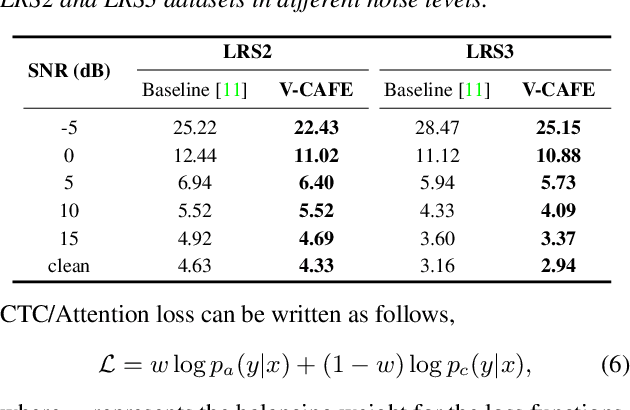
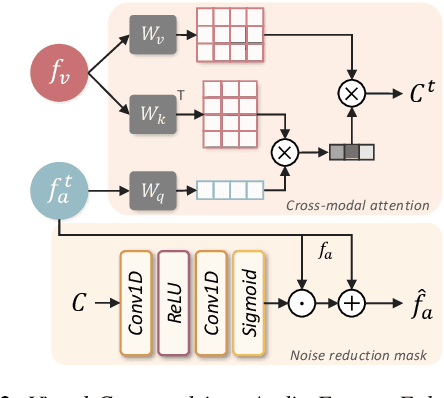
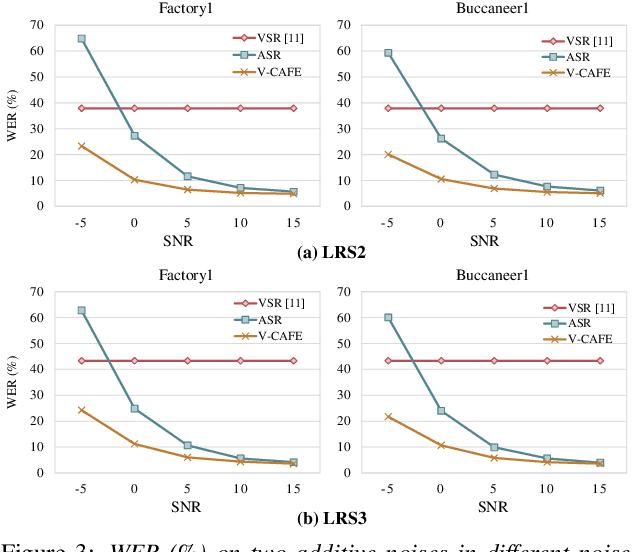
This paper focuses on designing a noise-robust end-to-end Audio-Visual Speech Recognition (AVSR) system. To this end, we propose Visual Context-driven Audio Feature Enhancement module (V-CAFE) to enhance the input noisy audio speech with a help of audio-visual correspondence. The proposed V-CAFE is designed to capture the transition of lip movements, namely visual context and to generate a noise reduction mask by considering the obtained visual context. Through context-dependent modeling, the ambiguity in viseme-to-phoneme mapping can be refined for mask generation. The noisy representations are masked out with the noise reduction mask resulting in enhanced audio features. The enhanced audio features are fused with the visual features and taken to an encoder-decoder model composed of Conformer and Transformer for speech recognition. We show the proposed end-to-end AVSR with the V-CAFE can further improve the noise-robustness of AVSR. The effectiveness of the proposed method is evaluated in noisy speech recognition and overlapped speech recognition experiments using the two largest audio-visual datasets, LRS2 and LRS3.