Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViSTRA3: Video Coding with Deep Parameter Adaptation and Post Processing
Paper and Code
Nov 30, 2021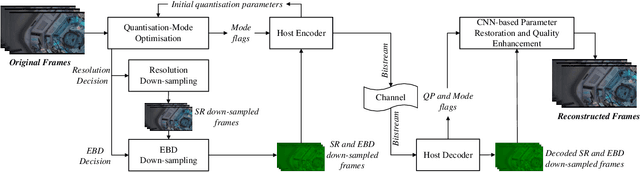
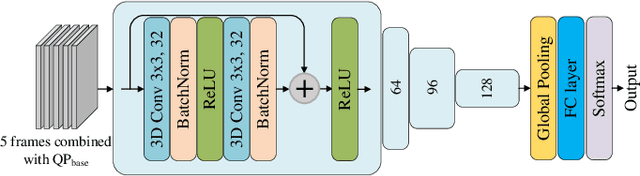
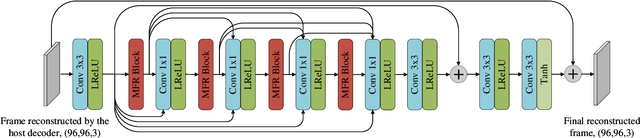
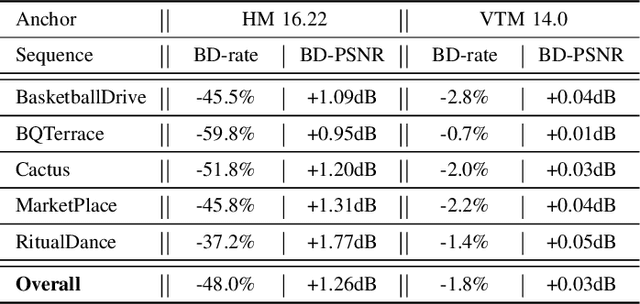
This paper presents a deep learning-based video compression framework (ViSTRA3). The proposed framework intelligently adapts video format parameters of the input video before encoding, subsequently employing a CNN at the decoder to restore their original format and enhance reconstruction quality. ViSTRA3 has been integrated with the H.266/VVC Test Model VTM 14.0, and evaluated under the Joint Video Exploration Team Common Test Conditions. Bj{\o}negaard Delta (BD) measurement results show that the proposed framework consistently outperforms the original VVC VTM, with average BD-rate savings of 1.8% and 3.7% based on the assessment of PSNR and VMAF.
View paper on