 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Depth Landmarks and Inertial Fusion for Navigation in Degraded Visual Environments
Paper and Code
Mar 05, 2019
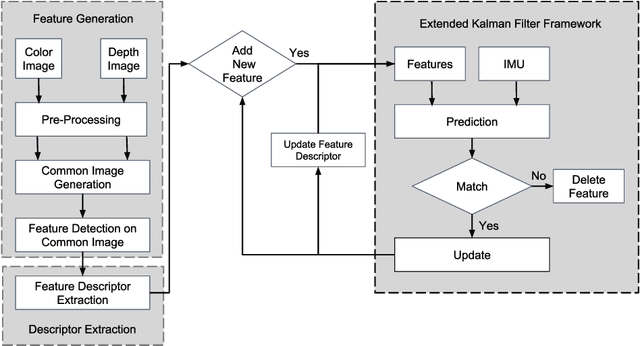


This paper proposes a method for tight fusion of visual, depth and inertial data in order to extend robotic capabilities for navigation in GPS-denied, poorly illuminated, and texture-less environments. Visual and depth information are fused at the feature detection and descriptor extraction levels to augment one sensing modality with the other. These multimodal features are then further integrated with inertial sensor cues using an extended Kalman filter to estimate the robot pose, sensor bias terms, and landmark positions simultaneously as part of the filter state. As demonstrated through a set of hand-held and Micro Aerial Vehicle experiments, the proposed algorithm is shown to perform reliably in challenging visually-degraded environments using RGB-D information from a lightweight and low-cost sensor and data from an IMU.