Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based Manipulation of Deformable and Rigid Objects Using Subspace Projections of 2D Contours
Paper and Code
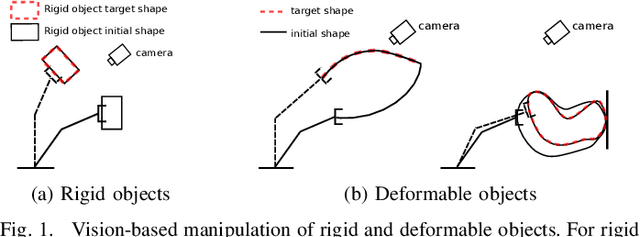
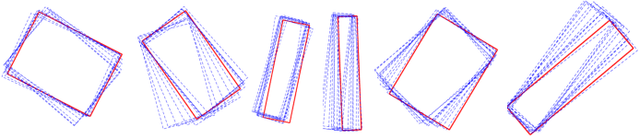
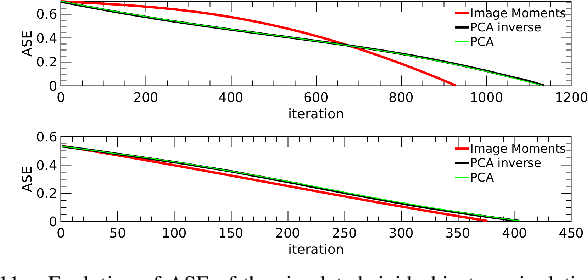
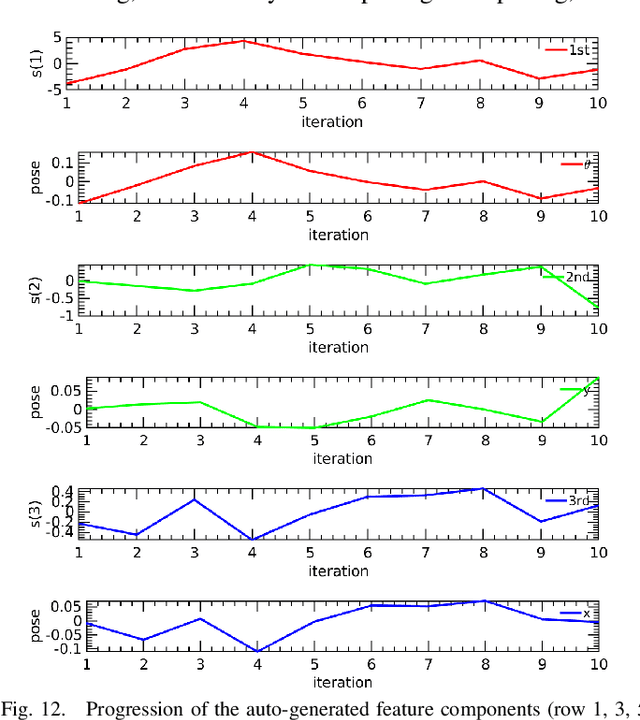
This paper proposes a unified vision-based manipulation framework using image contours of deformable/rigid objects. Instead of using human-defined cues, the robot automatically learns the features from processed vision data. Our method simultaneously generates---from the same data---both, visual features and the interaction matrix that relates them to the robot control inputs. Extraction of the feature vector and control commands is done online and adaptively, with little data for initialization. The method allows the robot to manipulate an object without knowing whether it is rigid or deformable. To validate our approach, we conduct numerical simulations and experiments with both deformable and rigid objects.
View paper on