 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis
Paper and Code
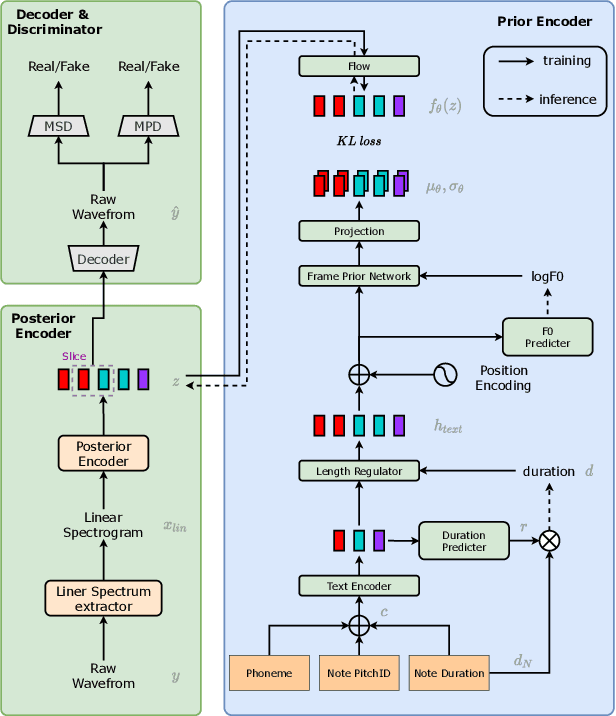
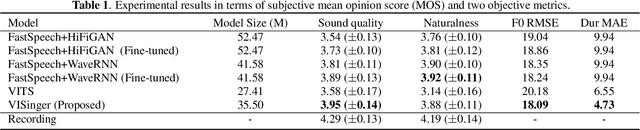
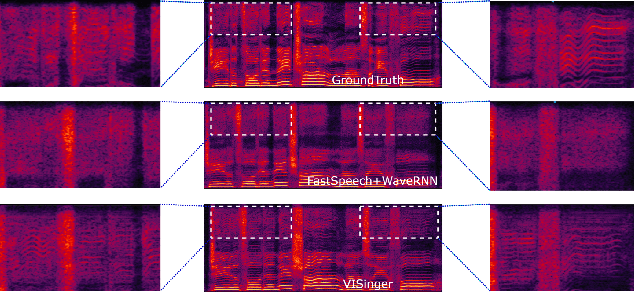
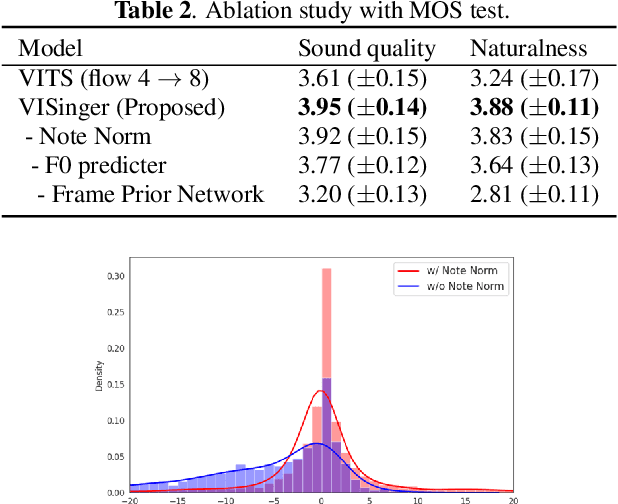
In this paper, we propose VISinger, a complete end-to-end high-quality singing voice synthesis (SVS) system that directly generates audio waveform from lyrics and musical score. Our approach is inspired by VITS, which adopts VAE-based posterior encoder augmented with normalizing flow-based prior encoder and adversarial decoder to realize complete end-to-end speech generation. VISinger follows the main architecture of VITS, but makes substantial improvements to the prior encoder based on the characteristics of singing. First, instead of using phoneme-level mean and variance of acoustic features, we introduce a length regulator and a frame prior network to get the frame-level mean and variance on acoustic features, modeling the rich acoustic variation in singing. Second, we further introduce an F0 predictor to guide the frame prior network, leading to stabler singing performance. Finally, to improve the singing rhythm, we modify the duration predictor to specifically predict the phoneme to note duration ratio, helped with singing note normalization. Experiments on a professional Mandarin singing corpus show that VISinger significantly outperforms FastSpeech+Neural-Vocoder two-stage approach and the oracle VITS; ablation study demonstrates the effectiveness of different contributions.