 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisageSynTalk: Unseen Speaker Video-to-Speech Synthesis via Speech-Visage Feature Selection
Paper and Code
Jun 15, 2022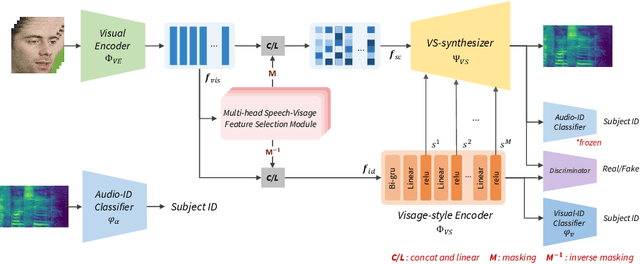
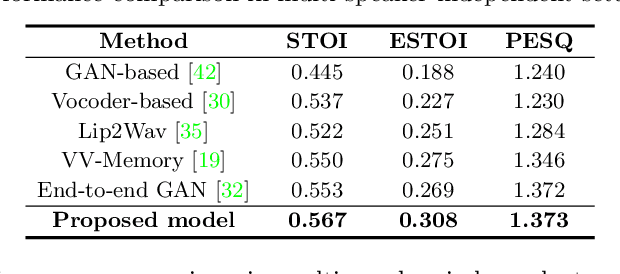
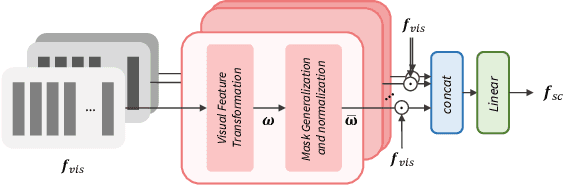
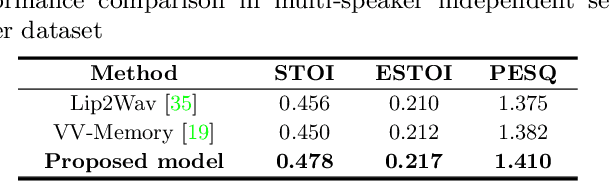
The goal of this work is to reconstruct speech from a silent talking face video. Recent studies have shown impressive performance on synthesizing speech from silent talking face videos. However, they have not explicitly considered on varying identity characteristics of different speakers, which place a challenge in the video-to-speech synthesis, and this becomes more critical in unseen-speaker settings. Distinct from the previous methods, our approach is to separate the speech content and the visage-style from a given silent talking face video. By guiding the model to independently focus on modeling the two representations, we can obtain the speech of high intelligibility from the model even when the input video of an unseen subject is given. To this end, we introduce speech-visage selection module that separates the speech content and the speaker identity from the visual features of the input video. The disentangled representations are jointly incorporated to synthesize speech through visage-style based synthesizer which generates speech by coating the visage-styles while maintaining the speech content. Thus, the proposed framework brings the advantage of synthesizing the speech containing the right content even when the silent talking face video of an unseen subject is given. We validate the effectiveness of the proposed framework on the GRID, TCD-TIMIT volunteer, and LRW datasets. The synthesized speech can be heard in supplementary materials.