 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Replay Cache
Paper and Code
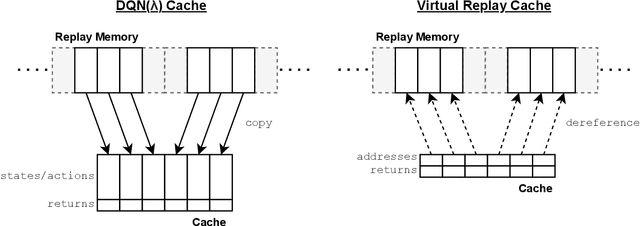
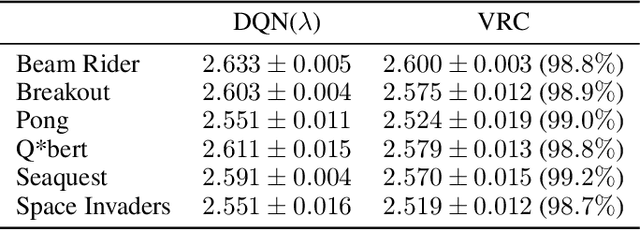

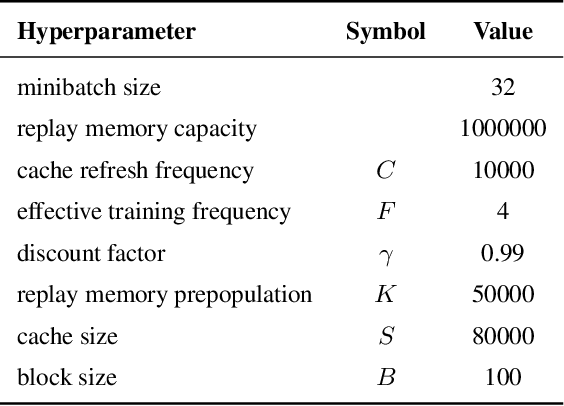
Return caching is a recent strategy that enables efficient minibatch training with multistep estimators (e.g. the {\lambda}-return) for deep reinforcement learning. By precomputing return estimates in sequential batches and then storing the results in an auxiliary data structure for later sampling, the average computation spent per estimate can be greatly reduced. Still, the efficiency of return caching could be improved, particularly with regard to its large memory usage and repetitive data copies. We propose a new data structure, the Virtual Replay Cache (VRC), to address these shortcomings. When learning to play Atari 2600 games, the VRC nearly eliminates DQN({\lambda})'s cache memory footprint and slightly reduces the total training time on our hardware.