Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRDO: Visio-tactile Implicit Representations of Deformable Objects
Paper and Code

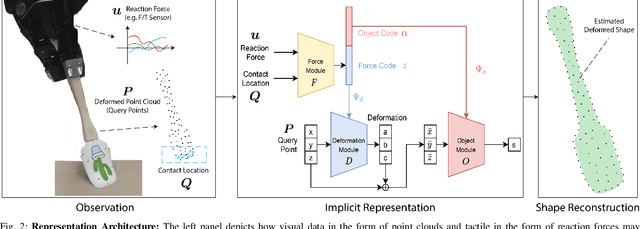
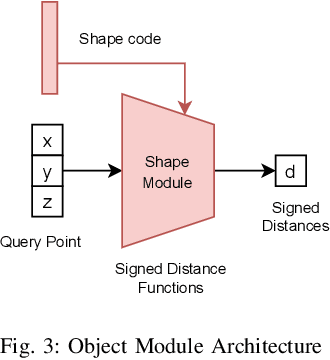

Deformable object manipulation requires computationally efficient representations that are compatible with robotic sensing modalities. In this paper, we present VIRDO:an implicit, multi-modal, and continuous representation for deformable-elastic objects. VIRDO operates directly on visual (point cloud) and tactile (reaction forces) modalities and learns rich latent embeddings of contact locations and forces to predict object deformations subject to external contacts.Here, we demonstrate VIRDOs ability to: i) produce high-fidelity cross-modal reconstructions with dense unsupervised correspondences, ii) generalize to unseen contact formations,and iii) state-estimation with partial visio-tactile feedback
* This work has been accepted to ICRA 2022
View paper on