 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRDO++: Real-World, Visuo-tactile Dynamics and Perception of Deformable Objects
Paper and Code
Oct 07, 2022

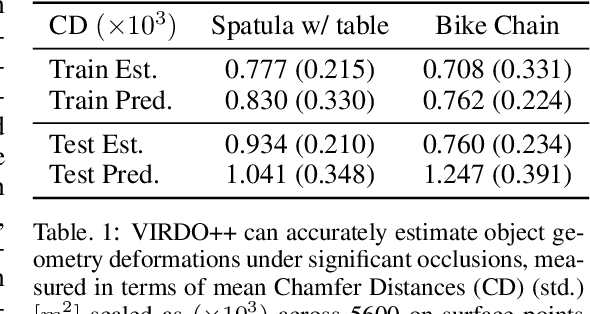
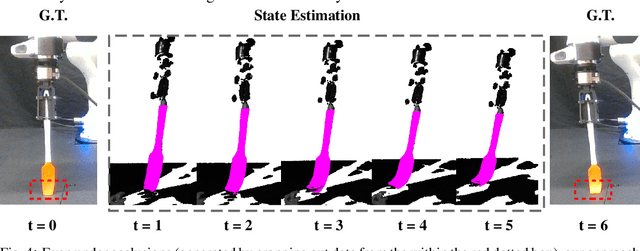
Deformable objects manipulation can benefit from representations that seamlessly integrate vision and touch while handling occlusions. In this work, we present a novel approach for, and real-world demonstration of, multimodal visuo-tactile state-estimation and dynamics prediction for deformable objects. Our approach, VIRDO++, builds on recent progress in multimodal neural implicit representations for deformable object state-estimation [1] via a new formulation for deformation dynamics and a complementary state-estimation algorithm that (i) maintains a belief over deformations, and (ii) enables practical real-world application by removing the need for privileged contact information. In the context of two real-world robotic tasks, we show:(i) high-fidelity cross-modal state-estimation and prediction of deformable objects from partial visuo-tactile feedback, and (ii) generalization to unseen objects and contact formations.