 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViGGO: A Video Game Corpus for Data-To-Text Generation in Open-Domain Conversation
Paper and Code
Oct 26, 2019

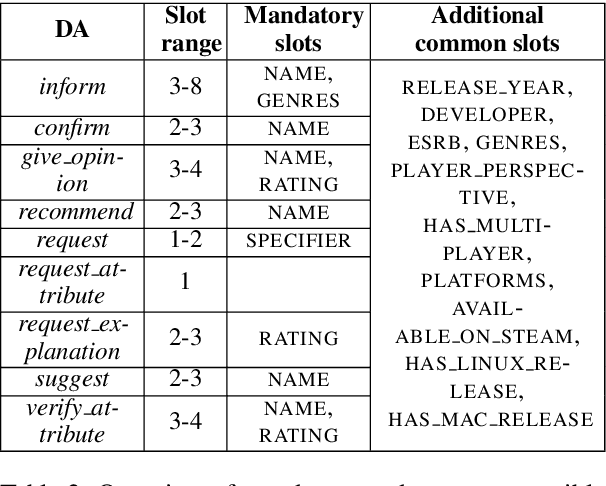

The uptake of deep learning in natural language generation (NLG) led to the release of both small and relatively large parallel corpora for training neural models. The existing data-to-text datasets are, however, aimed at task-oriented dialogue systems, and often thus limited in diversity and versatility. They are typically crowdsourced, with much of the noise left in them. Moreover, current neural NLG models do not take full advantage of large training data, and due to their strong generalizing properties produce sentences that look template-like regardless. We therefore present a new corpus of 7K samples, which (1) is clean despite being crowdsourced, (2) has utterances of 9 generalizable and conversational dialogue act types, making it more suitable for open-domain dialogue systems, and (3) explores the domain of video games, which is new to dialogue systems despite having excellent potential for supporting rich conversations.