 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIFIDEL: Evaluating the Visual Fidelity of Image Descriptions
Paper and Code
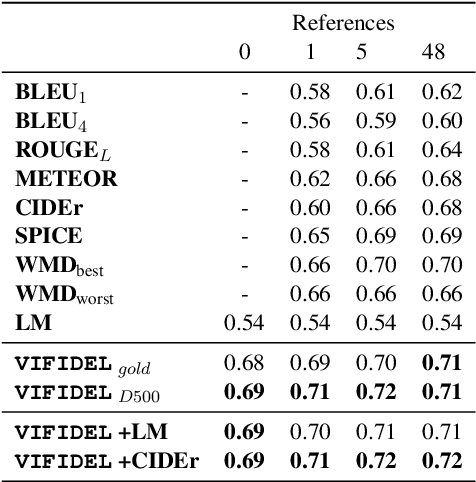
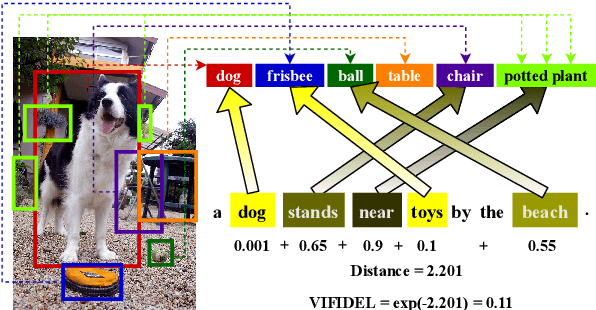
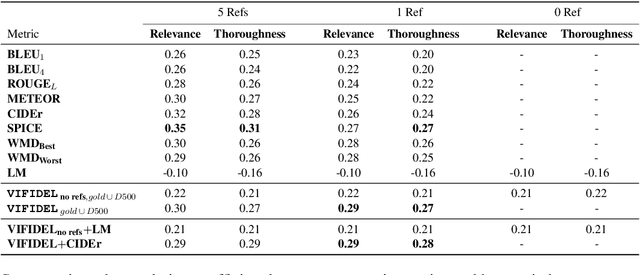
We address the task of evaluating image description generation systems. We propose a novel image-aware metric for this task: VIFIDEL. It estimates the faithfulness of a generated caption with respect to the content of the actual image, based on the semantic similarity between labels of objects depicted in images and words in the description. The metric is also able to take into account the relative importance of objects mentioned in human reference descriptions during evaluation. Even if these human reference descriptions are not available, VIFIDEL can still reliably evaluate system descriptions. The metric achieves high correlation with human judgments on two well-known datasets and is competitive with metrics that depend on human references