 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewmaker Networks: Learning Views for Unsupervised Representation Learning
Paper and Code


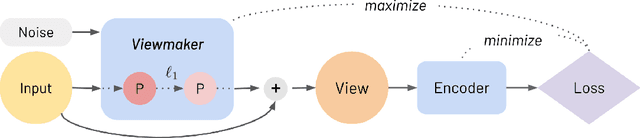
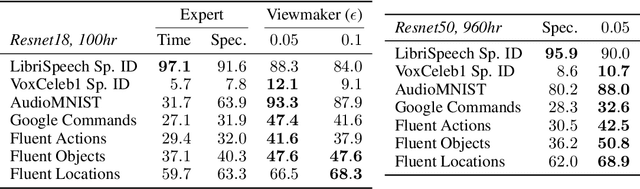
Many recent methods for unsupervised representation learning involve training models to be invariant to different "views," or transformed versions of an input. However, designing these views requires considerable human expertise and experimentation, hindering widespread adoption of unsupervised representation learning methods across domains and modalities. To address this, we propose viewmaker networks: generative models that learn to produce input-dependent views for contrastive learning. We train this network jointly with an encoder network to produce adversarial $\ell_p$ perturbations for an input, which yields challenging yet useful views without extensive human tuning. Our learned views, when applied to CIFAR-10, enable comparable transfer accuracy to the the well-studied augmentations used for the SimCLR model. Our views significantly outperforming baseline augmentations in speech (+9% absolute) and wearable sensor (+17% absolute) domains. We also show how viewmaker views can be combined with handcrafted views to improve robustness to common image corruptions. Our method demonstrates that learned views are a promising way to reduce the amount of expertise and effort needed for unsupervised learning, potentially extending its benefits to a much wider set of domains.