 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Diffusion Models are Training-free Motion Interpreter and Controller
Paper and Code

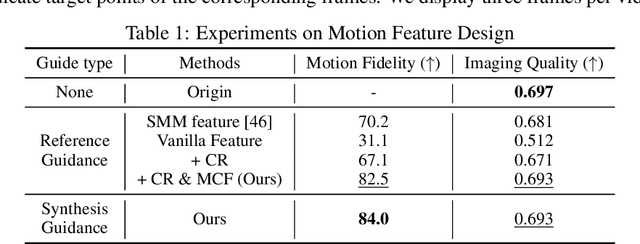
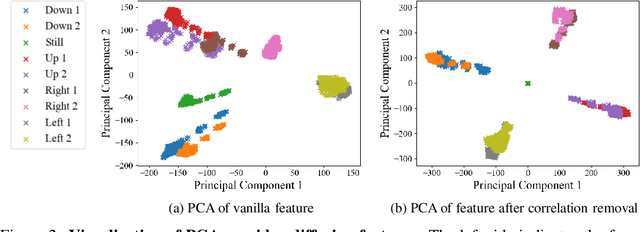
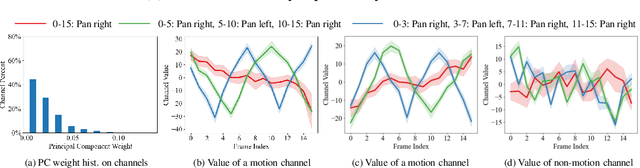
Video generation primarily aims to model authentic and customized motion across frames, making understanding and controlling the motion a crucial topic. Most diffusion-based studies on video motion focus on motion customization with training-based paradigms, which, however, demands substantial training resources and necessitates retraining for diverse models. Crucially, these approaches do not explore how video diffusion models encode cross-frame motion information in their features, lacking interpretability and transparency in their effectiveness. To answer this question, this paper introduces a novel perspective to understand, localize, and manipulate motion-aware features in video diffusion models. Through analysis using Principal Component Analysis (PCA), our work discloses that robust motion-aware feature already exists in video diffusion models. We present a new MOtion FeaTure (MOFT) by eliminating content correlation information and filtering motion channels. MOFT provides a distinct set of benefits, including the ability to encode comprehensive motion information with clear interpretability, extraction without the need for training, and generalizability across diverse architectures. Leveraging MOFT, we propose a novel training-free video motion control framework. Our method demonstrates competitive performance in generating natural and faithful motion, providing architecture-agnostic insights and applicability in a variety of downstream tasks.