 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVery Deep Multilingual Convolutional Neural Networks for LVCSR
Paper and Code
Jan 23, 2016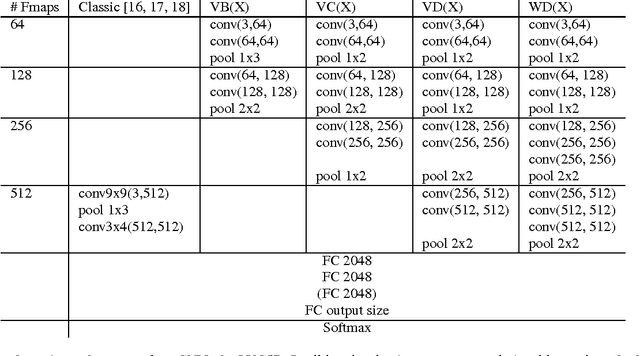
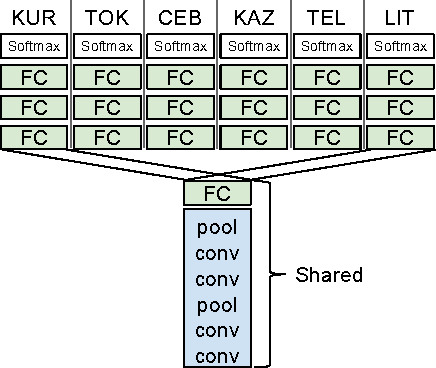


Convolutional neural networks (CNNs) are a standard component of many current state-of-the-art Large Vocabulary Continuous Speech Recognition (LVCSR) systems. However, CNNs in LVCSR have not kept pace with recent advances in other domains where deeper neural networks provide superior performance. In this paper we propose a number of architectural advances in CNNs for LVCSR. First, we introduce a very deep convolutional network architecture with up to 14 weight layers. There are multiple convolutional layers before each pooling layer, with small 3x3 kernels, inspired by the VGG Imagenet 2014 architecture. Then, we introduce multilingual CNNs with multiple untied layers. Finally, we introduce multi-scale input features aimed at exploiting more context at negligible computational cost. We evaluate the improvements first on a Babel task for low resource speech recognition, obtaining an absolute 5.77% WER improvement over the baseline PLP DNN by training our CNN on the combined data of six different languages. We then evaluate the very deep CNNs on the Hub5'00 benchmark (using the 262 hours of SWB-1 training data) achieving a word error rate of 11.8% after cross-entropy training, a 1.4% WER improvement (10.6% relative) over the best published CNN result so far.