 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Image Generation by Learning Parametric Layer Decomposition
Paper and Code
Dec 13, 2018

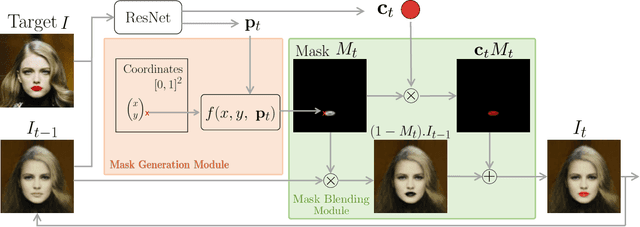
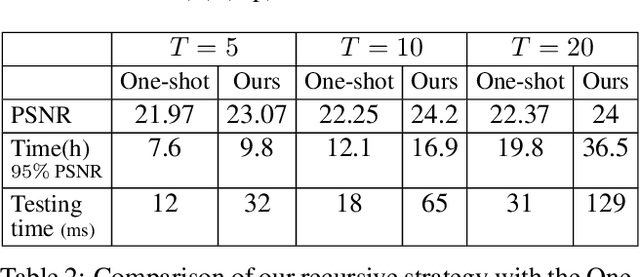
Deep image generation is becoming a tool to enhance artists and designers creativity potential. In this paper, we aim at making the generation process easier to understand and interact with. Inspired by vector graphics systems, we propose a new deep generation paradigm where the images are composed of simple layers, defined by their color and a parametric transparency mask. This presents a number of advantages compared to the commonly used convolutional network architectures. In particular, our layered decomposition allows simple user interaction, for example to update a given mask, or change the color of a selected layer. From a compact code, our architecture also generates images with a virtually infinite resolution, the color at each point in an image being a parametric function of its coordinates. We validate the viability of our approach in the auto-encoding framework by comparing reconstructions with state-of-the-art baselines given similar memory resources on CIFAR10, CelebA and ImageNet datasets and demonstrate several applications. We also show Generative Adversarial Network (GAN) results qualitatively different from the ones obtained with common approaches.