Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVBALD - Variational Bayesian Approximation of Log Determinants
Paper and Code
Feb 21, 2018
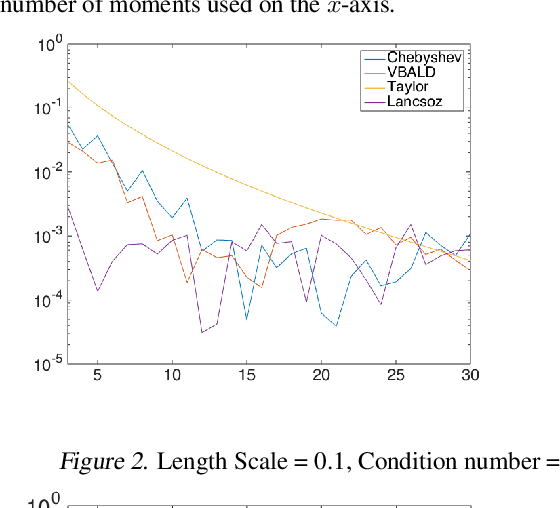
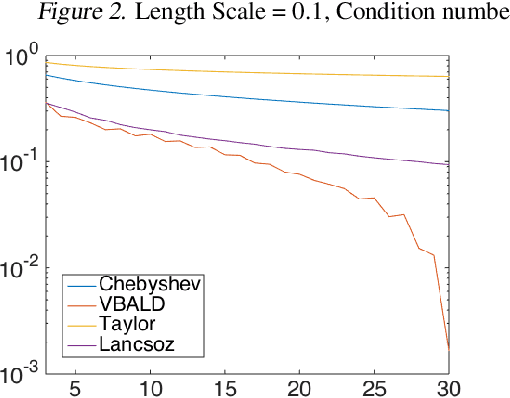

Evaluating the log determinant of a positive definite matrix is ubiquitous in machine learning. Applications thereof range from Gaussian processes, minimum-volume ellipsoids, metric learning, kernel learning, Bayesian neural networks, Determinental Point Processes, Markov random fields to partition functions of discrete graphical models. In order to avoid the canonical, yet prohibitive, Cholesky $\mathcal{O}(n^{3})$ computational cost, we propose a novel approach, with complexity $\mathcal{O}(n^{2})$, based on a constrained variational Bayes algorithm. We compare our method to Taylor, Chebyshev and Lanczos approaches and show state of the art performance on both synthetic and real-world datasets.
View paper on