 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariTex: Variational Neural Face Textures
Paper and Code
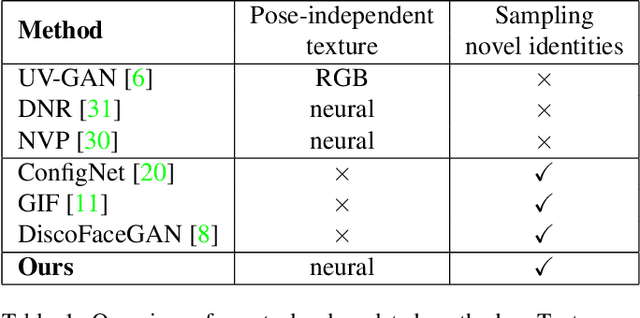
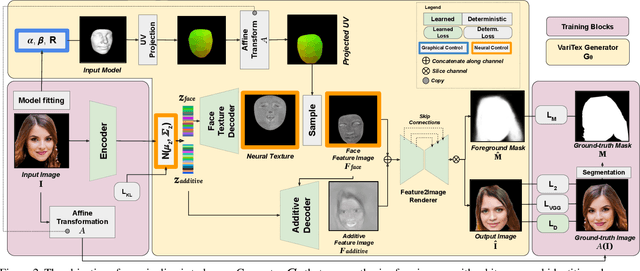


Deep generative models have recently demonstrated the ability to synthesize photorealistic images of human faces with novel identities. A key challenge to the wide applicability of such techniques is to provide independent control over semantically meaningful parameters: appearance, head pose, face shape, and facial expressions. In this paper, we propose VariTex - to the best of our knowledge the first method that learns a variational latent feature space of neural face textures, which allows sampling of novel identities. We combine this generative model with a parametric face model and gain explicit control over head pose and facial expressions. To generate images of complete human heads, we propose an additive decoder that generates plausible additional details such as hair. A novel training scheme enforces a pose independent latent space and in consequence, allows learning of a one-to-many mapping between latent codes and pose-conditioned exterior regions. The resulting method can generate geometrically consistent images of novel identities allowing fine-grained control over head pose, face shape, and facial expressions, facilitating a broad range of downstream tasks, like sampling novel identities, re-posing, expression transfer, and more.