 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Diffusion Auto-encoder: Deep Latent Variable Model with Unconditional Diffusion Prior
Paper and Code
Apr 24, 2023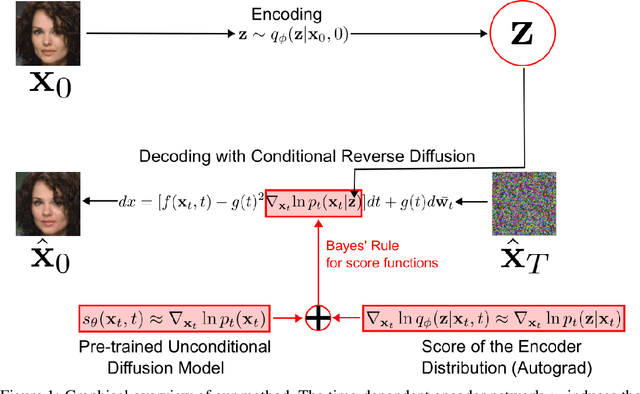



Variational auto-encoders (VAEs) are one of the most popular approaches to deep generative modeling. Despite their success, images generated by VAEs are known to suffer from blurriness, due to a highly unrealistic modeling assumption that the conditional data distribution $ p(\textbf{x} | \textbf{z})$ can be approximated as an isotropic Gaussian. In this work we introduce a principled approach to modeling the conditional data distribution $p(\textbf{x} | \textbf{z})$ by incorporating a diffusion model. We show that it is possible to create a VAE-like deep latent variable model without making the Gaussian assumption on $ p(\textbf{x} | \textbf{z}) $ or even training a decoder network. A trained encoder and an unconditional diffusion model can be combined via Bayes' rule for score functions to obtain an expressive model for $ p(\textbf{x} | \textbf{z}) $. Our approach avoids making strong assumptions on the parametric form of $ p(\textbf{x} | \textbf{z}) $, and thus allows to significantly improve the performance of VAEs.