 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-Biased Maximum Likelihood Estimation for Model-based Reinforcement Learning in Discounted Linear MDPs
Paper and Code
Oct 17, 2023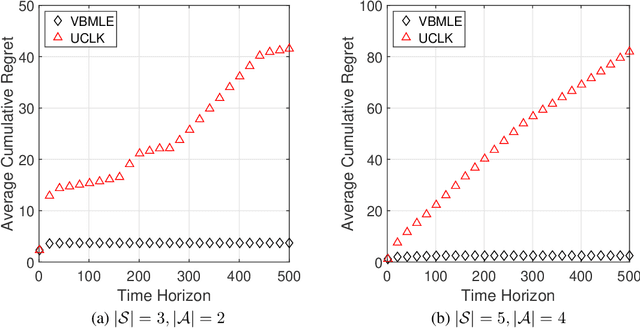

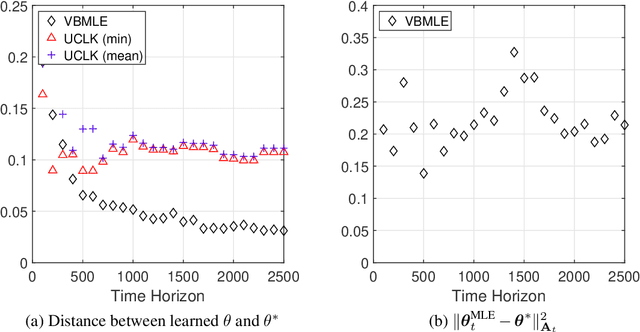

We consider the infinite-horizon linear Markov Decision Processes (MDPs), where the transition probabilities of the dynamic model can be linearly parameterized with the help of a predefined low-dimensional feature mapping. While the existing regression-based approaches have been theoretically shown to achieve nearly-optimal regret, they are computationally rather inefficient due to the need for a large number of optimization runs in each time step, especially when the state and action spaces are large. To address this issue, we propose to solve linear MDPs through the lens of Value-Biased Maximum Likelihood Estimation (VBMLE), which is a classic model-based exploration principle in the adaptive control literature for resolving the well-known closed-loop identification problem of Maximum Likelihood Estimation. We formally show that (i) VBMLE enjoys $\widetilde{O}(d\sqrt{T})$ regret, where $T$ is the time horizon and $d$ is the dimension of the model parameter, and (ii) VBMLE is computationally more efficient as it only requires solving one optimization problem in each time step. In our regret analysis, we offer a generic convergence result of MLE in linear MDPs through a novel supermartingale construct and uncover an interesting connection between linear MDPs and online learning, which could be of independent interest. Finally, the simulation results show that VBMLE significantly outperforms the benchmark method in terms of both empirical regret and computation time.