 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValNorm: A New Word Embedding Intrinsic Evaluation Method Reveals Valence Biases are Consistent Across Languages and Over Decades
Paper and Code

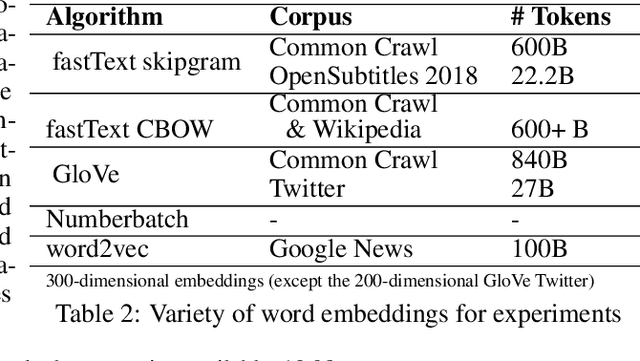

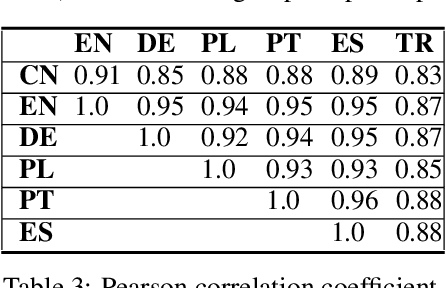
Word embeddings learn implicit biases from linguistic regularities captured by word co-occurrence information. As a result, statistical methods can detect and quantify social biases as well as widely shared associations imbibed by the corpus the word embeddings are trained on. By extending methods that quantify human-like biases in word embeddings, we introduce ValNorm, a new word embedding intrinsic evaluation task, and the first unsupervised method that estimates the affective meaning of valence in words with high accuracy. The correlation between human scores of valence for 399 words collected to establish pleasantness norms in English and ValNorm scores is r=0.88. These 399 words, obtained from social psychology literature, are used to measure biases that are non-discriminatory among social groups. We hypothesize that the valence associations for these words are widely shared across languages and consistent over time. We estimate valence associations of these words using word embeddings from six languages representing various language structures and from historical text covering 200 years. Our method achieves consistently high accuracy, suggesting that the valence associations for these words are widely shared. In contrast, we measure gender stereotypes using the same set of word embeddings and find that social biases vary across languages. Our results signal that valence associations of this word set represent widely shared associations and consequently an intrinsic quality of words.