Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating Hyperspectral Image Segmentation
Paper and Code
Nov 08, 2018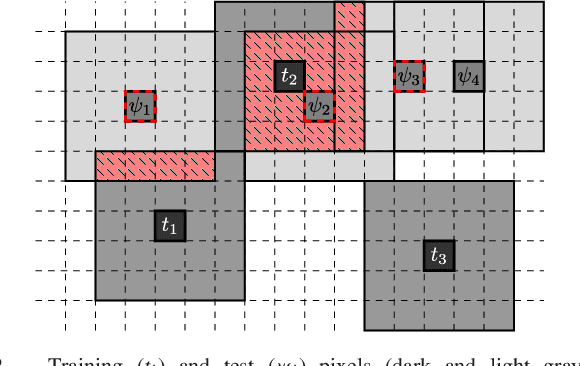

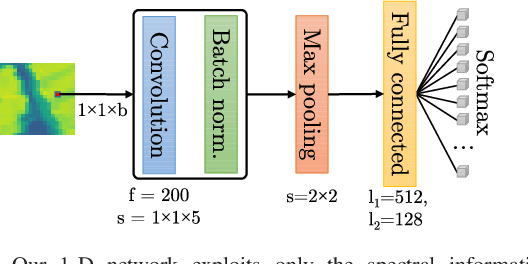

Hyperspectral satellite imaging attracts enormous research attention in the remote sensing community, hence automated approaches for precise segmentation of such imagery are being rapidly developed. In this letter, we share our observations on the strategy for validating hyperspectral image segmentation algorithms currently followed in the literature, and show that it can lead to over-optimistic experimental insights. We introduce a new routine for generating segmentation benchmarks, and use it to elaborate ready-to-use hyperspectral training-test data partitions. They can be utilized for fair validation of new and existing algorithms without any training-test data leakage.
* Submitted to IEEE Geoscience and Remote Sensing Letters
View paper on