 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-SlowFast Network for Efficient Visual Sound Separation
Paper and Code
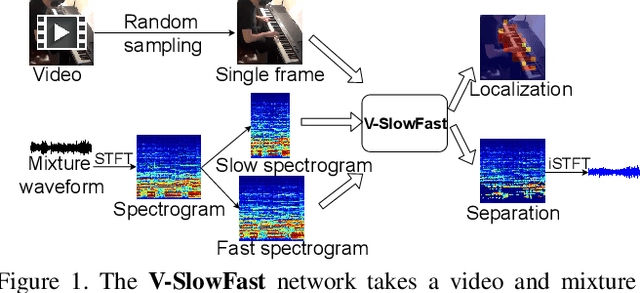

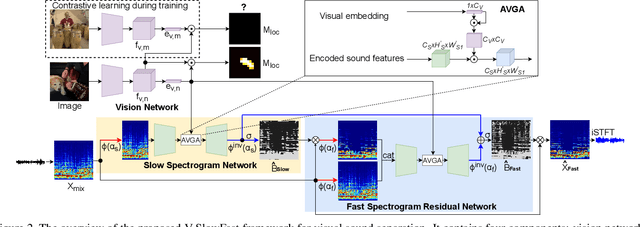
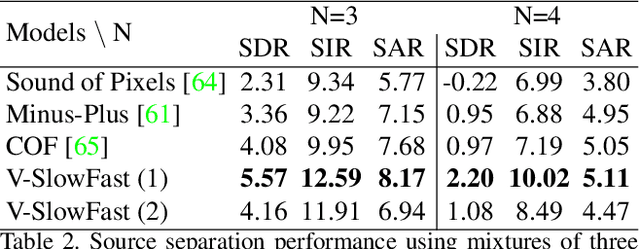
The objective of this paper is to perform visual sound separation: i) we study visual sound separation on spectrograms of different temporal resolutions; ii) we propose a new light yet efficient three-stream framework V-SlowFast that operates on Visual frame, Slow spectrogram, and Fast spectrogram. The Slow spectrogram captures the coarse temporal resolution while the Fast spectrogram contains the fine-grained temporal resolution; iii) we introduce two contrastive objectives to encourage the network to learn discriminative visual features for separating sounds; iv) we propose an audio-visual global attention module for audio and visual feature fusion; v) the introduced V-SlowFast model outperforms previous state-of-the-art in single-frame based visual sound separation on small- and large-scale datasets: MUSIC-21, AVE, and VGG-Sound. We also propose a small V-SlowFast architecture variant, which achieves 74.2% reduction in the number of model parameters and 81.4% reduction in GMACs compared to the previous multi-stage models. Project page: https://ly-zhu.github.io/V-SlowFast