Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Subset Log-Likelihoods to Trim Outliers in Gaussian Mixture Models
Paper and Code
Jul 02, 2019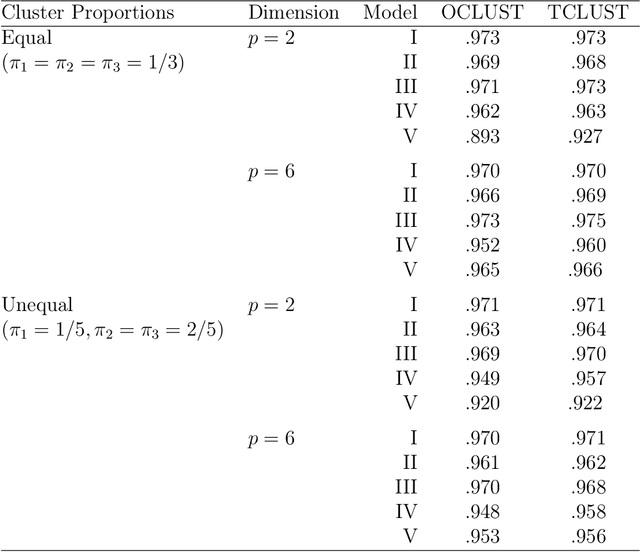
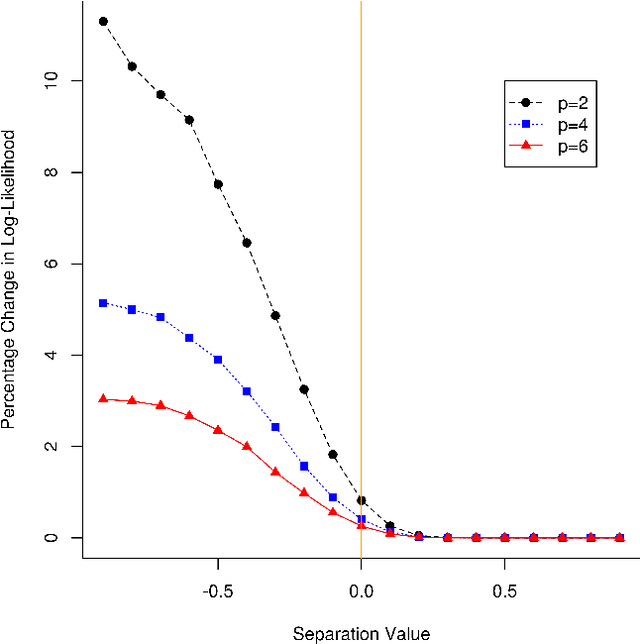
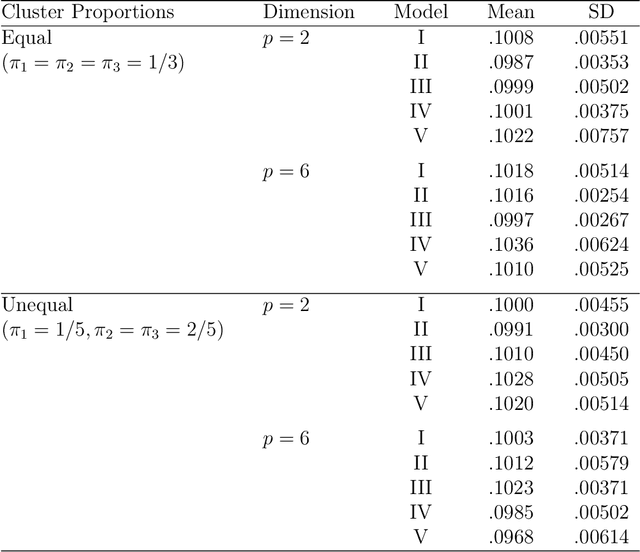
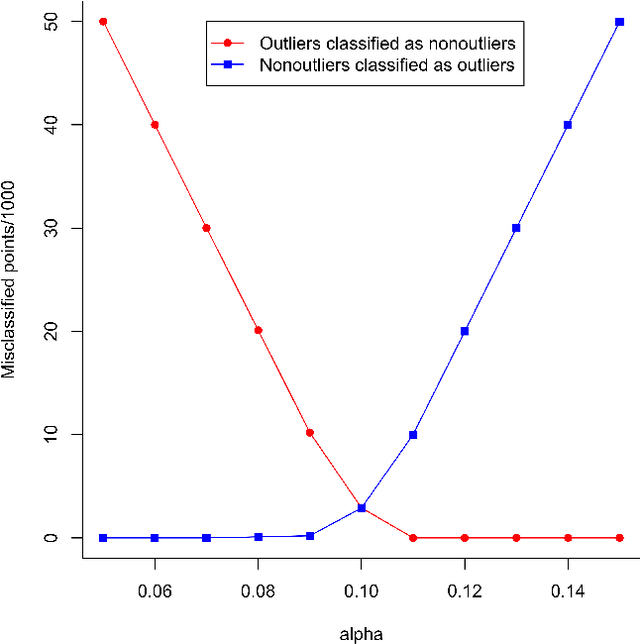
Mixtures of Gaussian distributions are a popular choice in model-based clustering. Outliers can affect parameters estimation and, as such, must be accounted for. Algorithms such as TCLUST discern the most likely outliers, but only when the proportion of outlying points is known \textit{a priori}. It is proved that, for a finite Gaussian mixture model, the log-likelihoods of the subset models are beta-distributed. An algorithm is then proposed that predicts the proportion of outliers by measuring the adherence of a set of subset log-likelihoods to a beta reference distribution. This algorithm removes the least likely points, which are deemed outliers, until model assumptions are met.
View paper on