 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Soft Labels to Model Uncertainty in Medical Image Segmentation
Paper and Code
Sep 26, 2021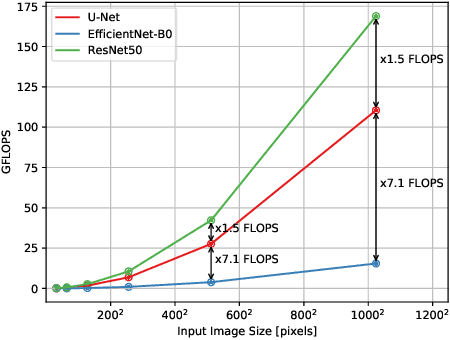
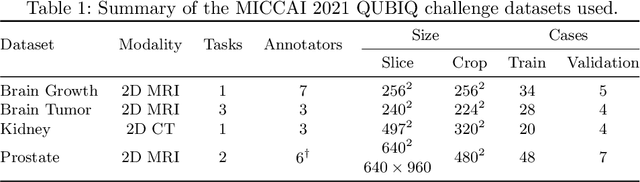
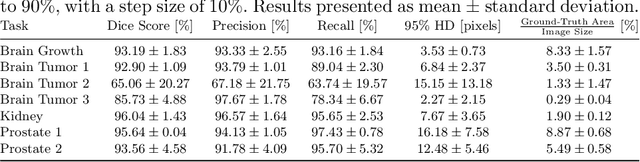
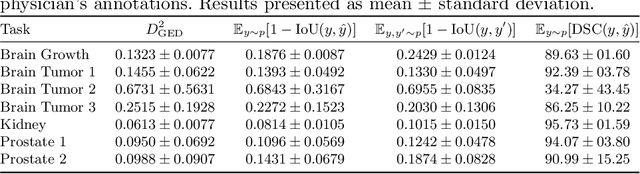
Medical image segmentation is inherently uncertain. For a given image, there may be multiple plausible segmentation hypotheses, and physicians will often disagree on lesion and organ boundaries. To be suited to real-world application, automatic segmentation systems must be able to capture this uncertainty and variability. Thus far, this has been addressed by building deep learning models that, through dropout, multiple heads, or variational inference, can produce a set - infinite, in some cases - of plausible segmentation hypotheses for any given image. However, in clinical practice, it may not be practical to browse all hypotheses. Furthermore, recent work shows that segmentation variability plateaus after a certain number of independent annotations, suggesting that a large enough group of physicians may be able to represent the whole space of possible segmentations. Inspired by this, we propose a simple method to obtain soft labels from the annotations of multiple physicians and train models that, for each image, produce a single well-calibrated output that can be thresholded at multiple confidence levels, according to each application's precision-recall requirements. We evaluated our method on the MICCAI 2021 QUBIQ challenge, showing that it performs well across multiple medical image segmentation tasks, produces well-calibrated predictions, and, on average, performs better at matching physicians' predictions than other physicians.