 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Monte Carlo Tree Search as a Demonstrator within Asynchronous Deep RL
Paper and Code
Nov 30, 2018
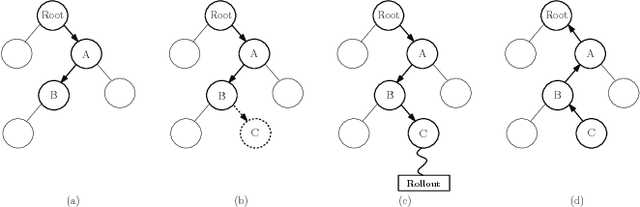
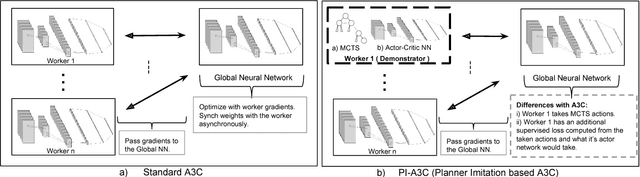

Deep reinforcement learning (DRL) has achieved great successes in recent years with the help of novel methods and higher compute power. However, there are still several challenges to be addressed such as convergence to locally optimal policies and long training times. In this paper, firstly, we augment Asynchronous Advantage Actor-Critic (A3C) method with a novel self-supervised auxiliary task, i.e. \emph{Terminal Prediction}, measuring temporal closeness to terminal states, namely A3C-TP. Secondly, we propose a new framework where planning algorithms such as Monte Carlo tree search or other sources of (simulated) demonstrators can be integrated to asynchronous distributed DRL methods. Compared to vanilla A3C, our proposed methods both learn faster and converge to better policies on a two-player mini version of the Pommerman game.