 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSCORE: An Effective Approach to Fully Unsupervised Evaluation Metrics for Machine Translation
Paper and Code
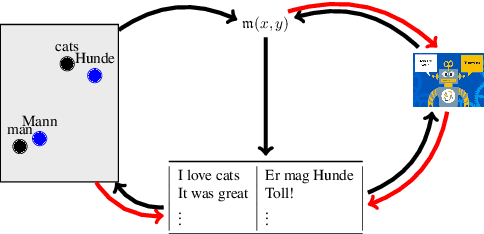
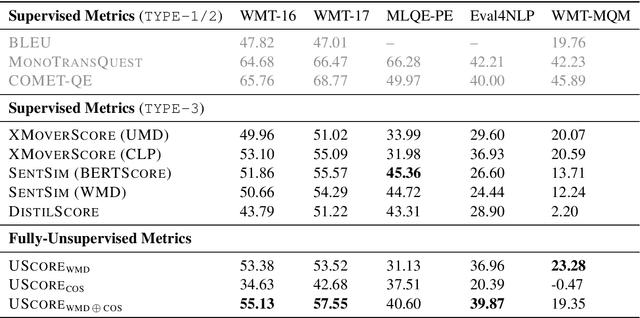
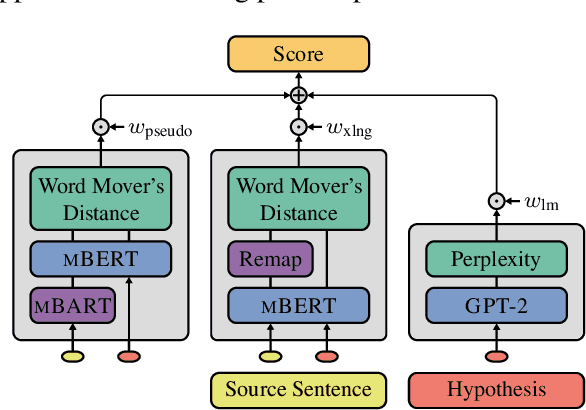
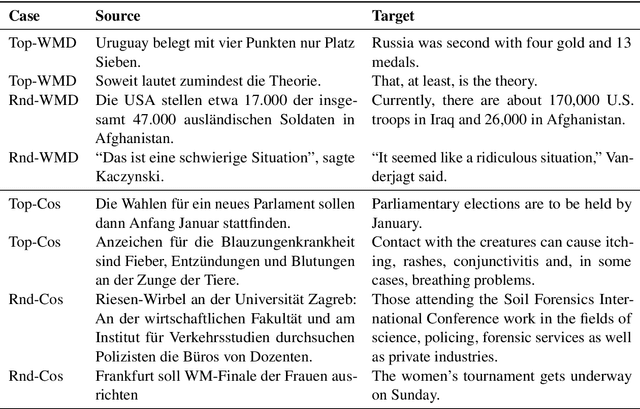
The vast majority of evaluation metrics for machine translation are supervised, i.e., (i) assume the existence of reference translations, (ii) are trained on human scores, or (iii) leverage parallel data. This hinders their applicability to cases where such supervision signals are not available. In this work, we develop fully unsupervised evaluation metrics. To do so, we leverage similarities and synergies between evaluation metric induction, parallel corpus mining, and MT systems. In particular, we use an unsupervised evaluation metric to mine pseudo-parallel data, which we use to remap deficient underlying vector spaces (in an iterative manner) and to induce an unsupervised MT system, which then provides pseudo-references as an additional component in the metric. Finally, we also induce unsupervised multilingual sentence embeddings from pseudo-parallel data. We show that our fully unsupervised metrics are effective, i.e., they beat supervised competitors on 4 out of our 5 evaluation datasets.