 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPB at SemEval-2020 Task 6: Pretrained Language Models for Definition Extraction
Paper and Code

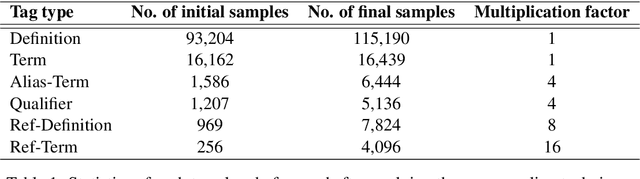
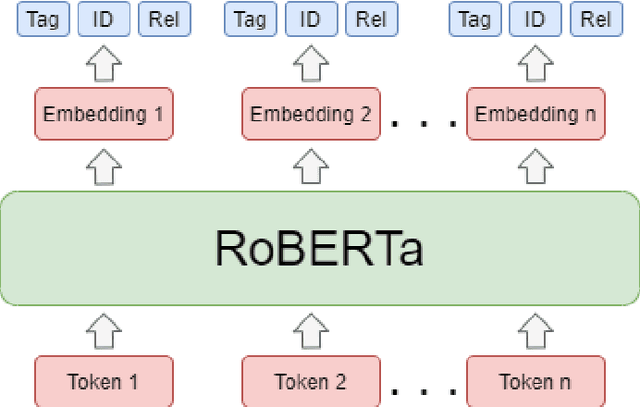
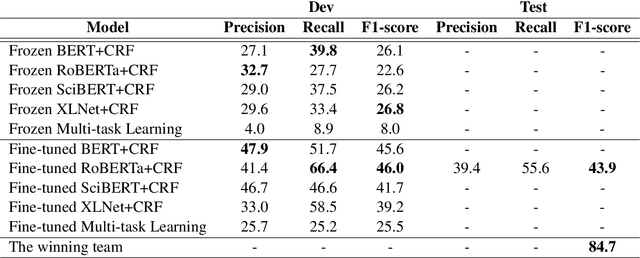
This work presents our contribution in the context of the 6th task of SemEval-2020: Extracting Definitions from Free Text in Textbooks (DeftEval). This competition consists of three subtasks with different levels of granularity: (1) classification of sentences as definitional or non-definitional,(2) labeling of definitional sentences, and (3) relation classification. We use various pretrained language models (i.e., BERT, XLNet, RoBERTa, SciBERT, and ALBERT) to solve each of the three subtasks of the competition. Specifically, for each language model variant, we experiment by both freezing its weights and fine-tuning them. We also explore a multi-task architecture that was trained to jointly predict the outputs for the second and the third subtasks. Our best performing model evaluated on the DeftEval dataset obtains the 32nd place for the first subtask and the 37th place for the second subtask. The code is available for further research at: https://github.com/avramandrei/DeftEval.