 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntangling Gaussian Mixtures
Paper and Code
Mar 11, 2024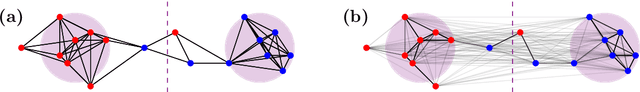
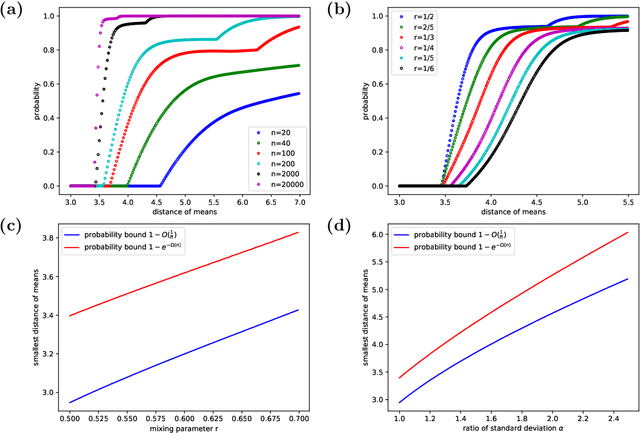

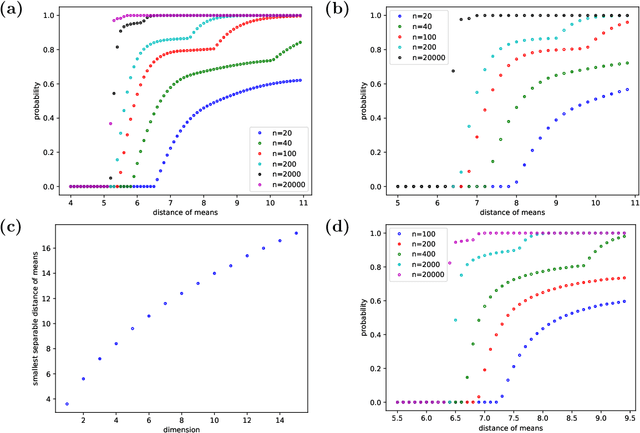
Tangles were originally introduced as a concept to formalize regions of high connectivity in graphs. In recent years, they have also been discovered as a link between structural graph theory and data science: when interpreting similarity in data sets as connectivity between points, finding clusters in the data essentially amounts to finding tangles in the underlying graphs. This paper further explores the potential of tangles in data sets as a means for a formal study of clusters. Real-world data often follow a normal distribution. Accounting for this, we develop a quantitative theory of tangles in data sets drawn from Gaussian mixtures. To this end, we equip the data with a graph structure that models similarity between the points and allows us to apply tangle theory to the data. We provide explicit conditions under which tangles associated with the marginal Gaussian distributions exist asymptotically almost surely. This can be considered as a sufficient formal criterion for the separabability of clusters in the data.