 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Visual Representation Learning by Online Constrained K-Means
Paper and Code
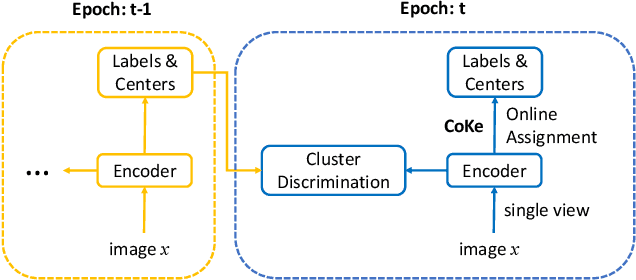
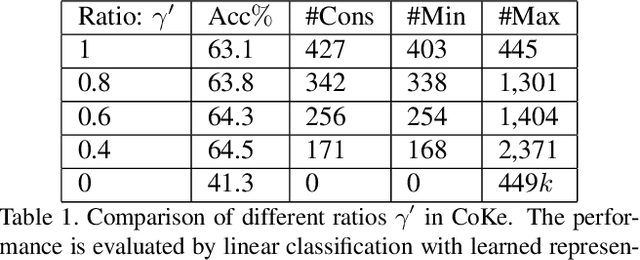
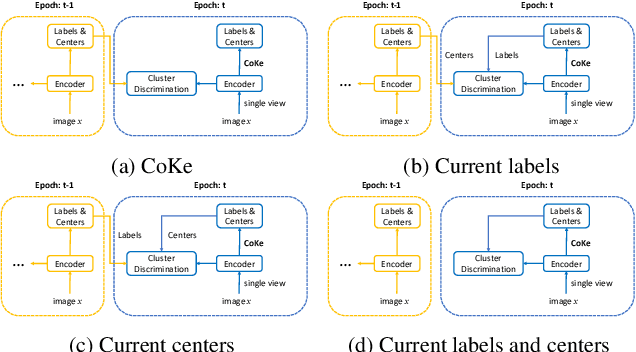
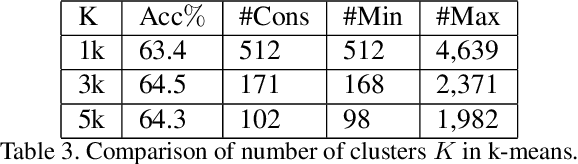
Cluster discrimination is an effective pretext task for unsupervised representation learning, which often consists of two phases: clustering and discrimination. Clustering is to assign each instance a pseudo label that will be used to learn representations in discrimination. The main challenge resides in clustering since many prevalent clustering methods (e.g., k-means) have to run in a batch mode that goes multiple iterations over the whole data. Recently, a balanced online clustering method, i.e., SwAV, is proposed for representation learning. However, the assignment is optimized within only a small subset of data, which can be suboptimal. To address these challenges, we first investigate the objective of clustering-based representation learning from the perspective of distance metric learning. Based on this, we propose a novel clustering-based pretext task with online \textbf{Co}nstrained \textbf{K}-m\textbf{e}ans (\textbf{CoKe}) to learn representations and relations between instances simultaneously. Compared with the balanced clustering that each cluster has exactly the same size, we only constrain the minimum size of clusters to flexibly capture the inherent data structure. More importantly, our online assignment method has a theoretical guarantee to approach the global optimum. Finally, two variance reduction strategies are proposed to make the clustering robust for different augmentations. Without keeping representations of instances, the data is accessed in an online mode in CoKe while a single view of instances at each iteration is sufficient to demonstrate a better performance than contrastive learning methods relying on two views. Extensive experiments on ImageNet verify the efficacy of our proposal. Code will be released.