 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Symbolic Music Segmentation using Ensemble Temporal Prediction Errors
Paper and Code
Jul 02, 2022
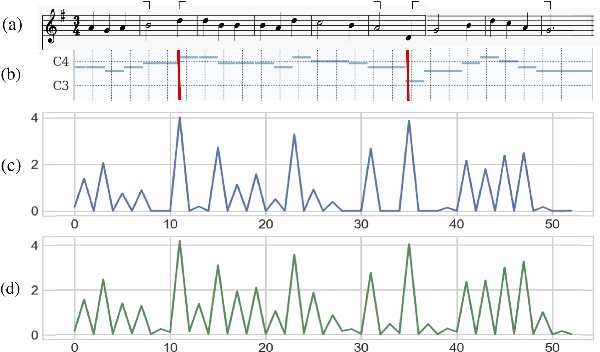
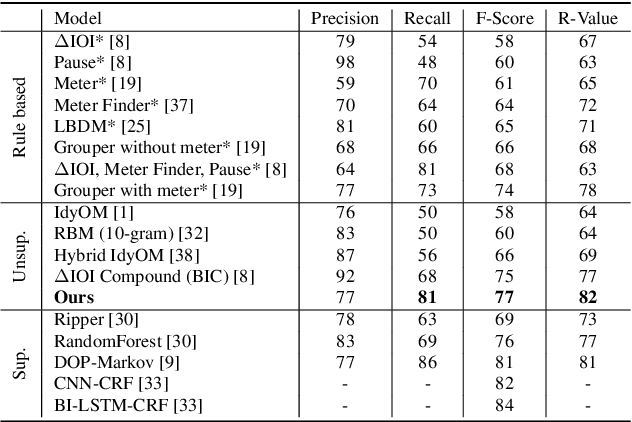
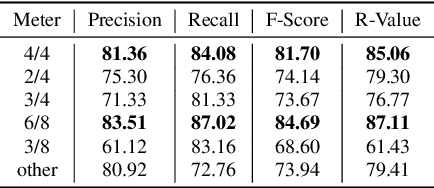
Symbolic music segmentation is the process of dividing symbolic melodies into smaller meaningful groups, such as melodic phrases. We proposed an unsupervised method for segmenting symbolic music. The proposed model is based on an ensemble of temporal prediction error models. During training, each model predicts the next token to identify musical phrase changes. While at test time, we perform a peak detection algorithm to select segment candidates. Finally, we aggregate the predictions of each of the models participating in the ensemble to predict the final segmentation. Results suggest the proposed method reaches state-of-the-art performance on the Essen Folksong dataset under the unsupervised setting when considering F-Score and R-value. We additionally provide an ablation study to better assess the contribution of each of the model components to the final results. As expected, the proposed method is inferior to the supervised setting, which leaves room for improvement in future research considering closing the gap between unsupervised and supervised methods.