 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pre-Training on Patient Population Graphs for Patient-Level Predictions
Paper and Code
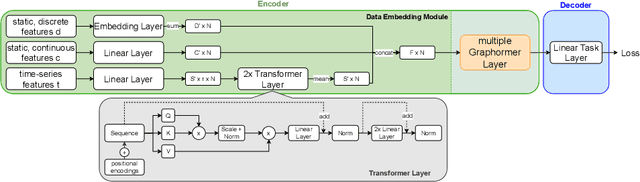

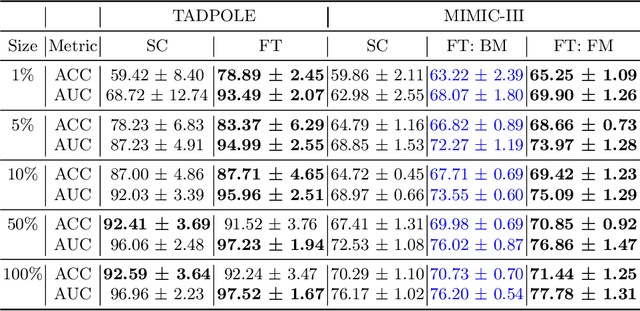
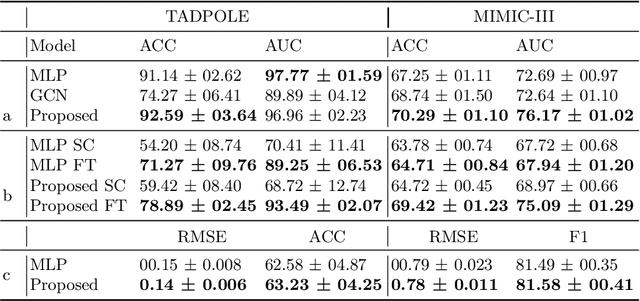
Pre-training has shown success in different areas of machine learning, such as Computer Vision (CV), Natural Language Processing (NLP) and medical imaging. However, it has not been fully explored for clinical data analysis. Even though an immense amount of Electronic Health Record (EHR) data is recorded, data and labels can be scarce if the data is collected in small hospitals or deals with rare diseases. In such scenarios, pre-training on a larger set of EHR data could improve the model performance. In this paper, we apply unsupervised pre-training to heterogeneous, multi-modal EHR data for patient outcome prediction. To model this data, we leverage graph deep learning over population graphs. We first design a network architecture based on graph transformer designed to handle various input feature types occurring in EHR data, like continuous, discrete, and time-series features, allowing better multi-modal data fusion. Further, we design pre-training methods based on masked imputation to pre-train our network before fine-tuning on different end tasks. Pre-training is done in a fully unsupervised fashion, which lays the groundwork for pre-training on large public datasets with different tasks and similar modalities in the future. We test our method on two medical datasets of patient records, TADPOLE and MIMIC-III, including imaging and non-imaging features and different prediction tasks. We find that our proposed graph based pre-training method helps in modeling the data at a population level and further improves performance on the fine tuning tasks in terms of AUC on average by 4.15% for MIMIC and 7.64% for TADPOLE.