 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised pre-training of graph transformers on patient population graphs
Paper and Code
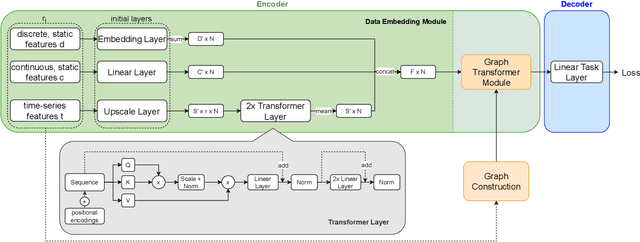
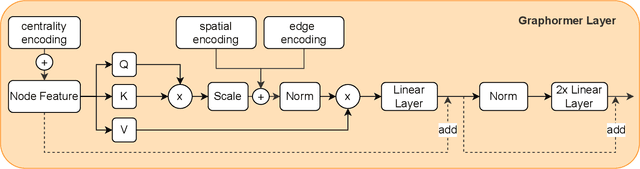
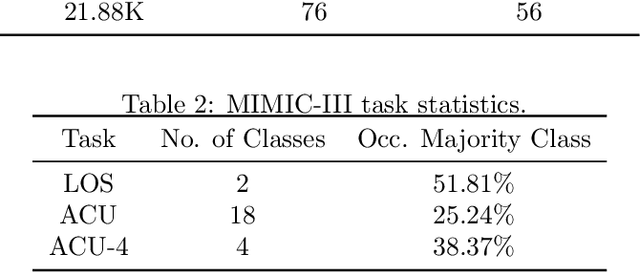
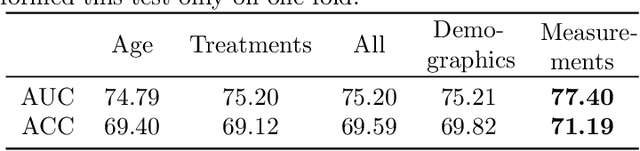
Pre-training has shown success in different areas of machine learning, such as Computer Vision, Natural Language Processing (NLP), and medical imaging. However, it has not been fully explored for clinical data analysis. An immense amount of clinical records are recorded, but still, data and labels can be scarce for data collected in small hospitals or dealing with rare diseases. In such scenarios, pre-training on a larger set of unlabelled clinical data could improve performance. In this paper, we propose novel unsupervised pre-training techniques designed for heterogeneous, multi-modal clinical data for patient outcome prediction inspired by masked language modeling (MLM), by leveraging graph deep learning over population graphs. To this end, we further propose a graph-transformer-based network, designed to handle heterogeneous clinical data. By combining masking-based pre-training with a transformer-based network, we translate the success of masking-based pre-training in other domains to heterogeneous clinical data. We show the benefit of our pre-training method in a self-supervised and a transfer learning setting, utilizing three medical datasets TADPOLE, MIMIC-III, and a Sepsis Prediction Dataset. We find that our proposed pre-training methods help in modeling the data at a patient and population level and improve performance in different fine-tuning tasks on all datasets.