 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Motion Representation Enhanced Network for Action Recognition
Paper and Code
Mar 05, 2021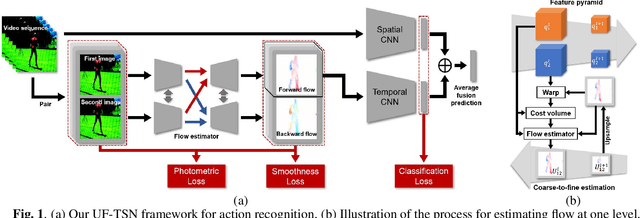



Learning reliable motion representation between consecutive frames, such as optical flow, has proven to have great promotion to video understanding. However, the TV-L1 method, an effective optical flow solver, is time-consuming and expensive in storage for caching the extracted optical flow. To fill the gap, we propose UF-TSN, a novel end-to-end action recognition approach enhanced with an embedded lightweight unsupervised optical flow estimator. UF-TSN estimates motion cues from adjacent frames in a coarse-to-fine manner and focuses on small displacement for each level by extracting pyramid of feature and warping one to the other according to the estimated flow of the last level. Due to the lack of labeled motion for action datasets, we constrain the flow prediction with multi-scale photometric consistency and edge-aware smoothness. Compared with state-of-the-art unsupervised motion representation learning methods, our model achieves better accuracy while maintaining efficiency, which is competitive with some supervised or more complicated approaches.