 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Face Representations
Paper and Code
Mar 03, 2018

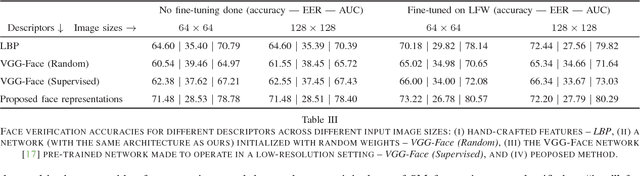
We present an approach for unsupervised training of CNNs in order to learn discriminative face representations. We mine supervised training data by noting that multiple faces in the same video frame must belong to different persons and the same face tracked across multiple frames must belong to the same person. We obtain millions of face pairs from hundreds of videos without using any manual supervision. Although faces extracted from videos have a lower spatial resolution than those which are available as part of standard supervised face datasets such as LFW and CASIA-WebFace, the former represent a much more realistic setting, e.g. in surveillance scenarios where most of the faces detected are very small. We train our CNNs with the relatively low resolution faces extracted from video frames collected, and achieve a higher verification accuracy on the benchmark LFW dataset cf. hand-crafted features such as LBPs, and even surpasses the performance of state-of-the-art deep networks such as VGG-Face, when they are made to work with low resolution input images.