 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Graph-Structured Data Using Class-Conditional Distribution Alignment
Paper and Code
Jan 29, 2023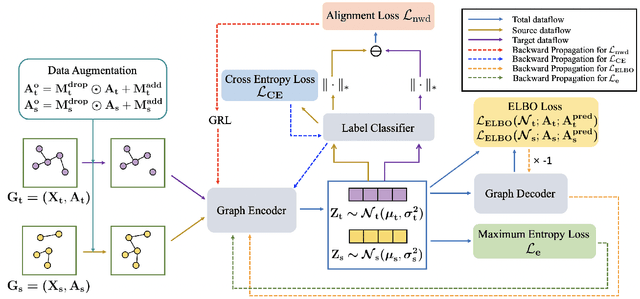
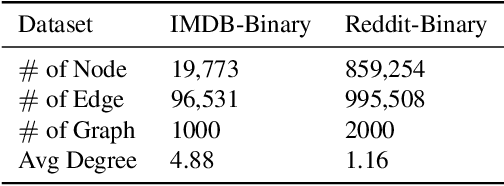
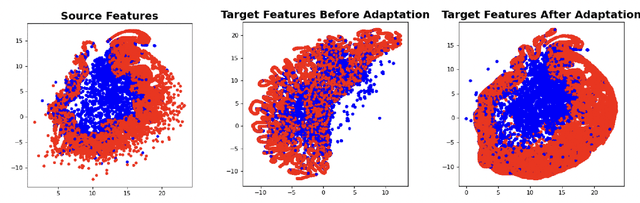
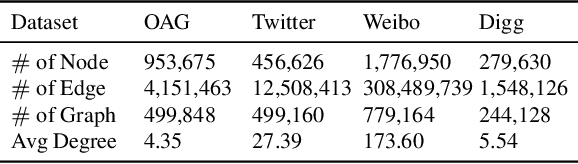
Adopting deep learning models for graph-structured data is challenging due to the high cost of collecting and annotating large training data. Unsupervised domain adaptation (UDA) has been used successfully to address the challenge of data annotation for array-structured data. However, UDA methods for graph-structured data are quite limited. We develop a novel UDA algorithm for graph-structured data based on aligning the distribution of the target domain with unannotated data with the distribution of a source domain with annotated data in a shared embedding space. Specifically, we minimize both the sliced Wasserstein distance (SWD) and the maximum mean discrepancy (MMD) between the distributions of the source and the target domains at the output of graph encoding layers. Moreover, we develop a novel pseudo-label generation technique to align the distributions class-conditionally to address the challenge of class mismatch. Our empirical results on the Ego-network and the IMDB$\&$Reddit datasets demonstrate that our method is effective and leads to state-of-the-art performance.