 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Adaptation of Semantic Segmentation Models without Source Data
Paper and Code
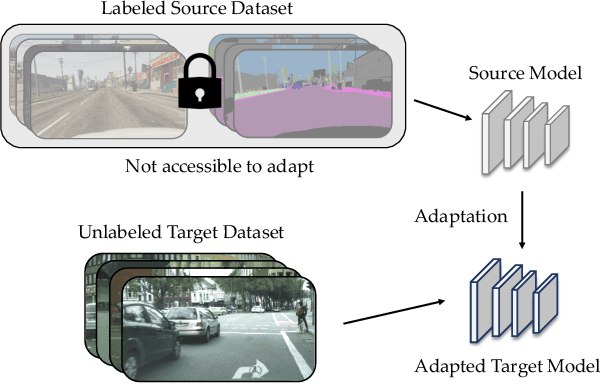
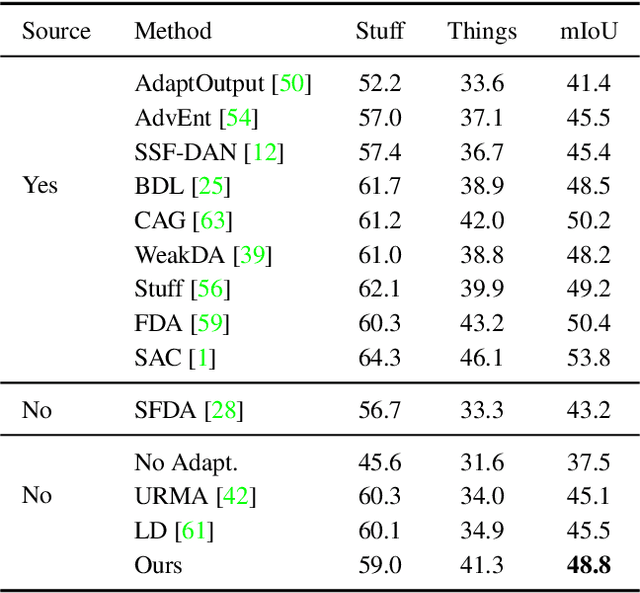
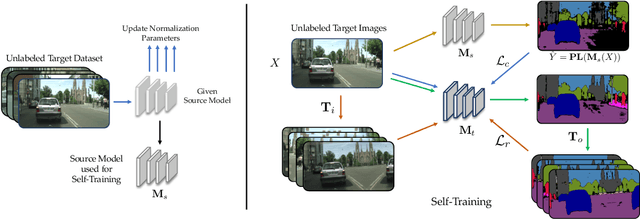
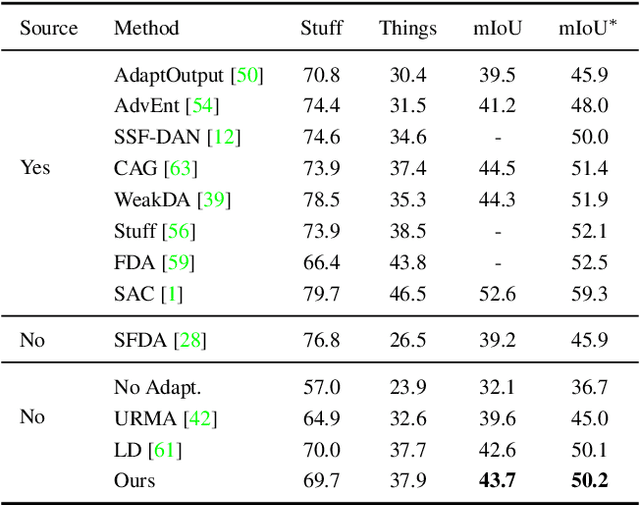
We consider the novel problem of unsupervised domain adaptation of source models, without access to the source data for semantic segmentation. Unsupervised domain adaptation aims to adapt a model learned on the labeled source data, to a new unlabeled target dataset. Existing methods assume that the source data is available along with the target data during adaptation. However, in practical scenarios, we may only have access to the source model and the unlabeled target data, but not the labeled source, due to reasons such as privacy, storage, etc. In this work, we propose a self-training approach to extract the knowledge from the source model. To compensate for the distribution shift from source to target, we first update only the normalization parameters of the network with the unlabeled target data. Then we employ confidence-filtered pseudo labeling and enforce consistencies against certain transformations. Despite being very simple and intuitive, our framework is able to achieve significant performance gains compared to directly applying the source model on the target data as reflected in our extensive experiments and ablation studies. In fact, the performance is just a few points away from the recent state-of-the-art methods which use source data for adaptation. We further demonstrate the generalisability of the proposed approach for fully test-time adaptation setting, where we do not need any target training data and adapt only during test-time.