 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrolling SGD: Understanding Factors Influencing Machine Unlearning
Paper and Code
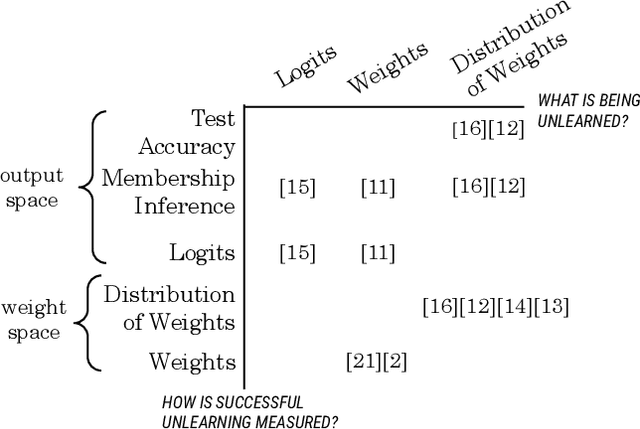
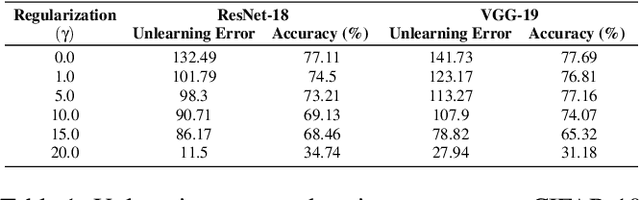
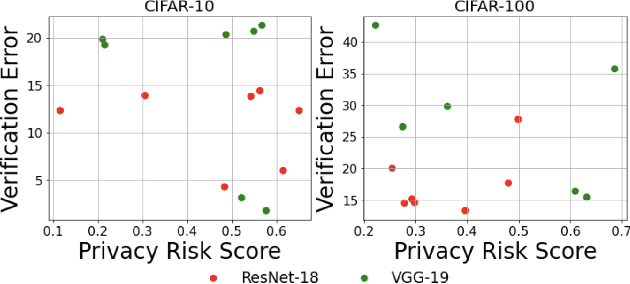
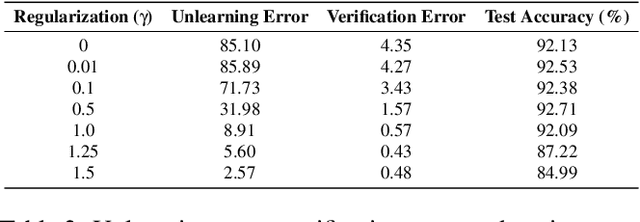
Machine unlearning is the process through which a deployed machine learning model forgets about one of its training data points. While naively retraining the model from scratch is an option, it is almost always associated with a large computational effort for deep learning models. Thus, several approaches to approximately unlearn have been proposed along with corresponding metrics that formalize what it means for a model to forget about a data point. In this work, we first taxonomize approaches and metrics of approximate unlearning. As a result, we identify verification error, i.e., the L2 difference between the weights of an approximately unlearned and a naively retrained model, as a metric approximate unlearning should optimize for as it implies a large class of other metrics. We theoretically analyze the canonical stochastic gradient descent (SGD) training algorithm to surface the variables which are relevant to reducing the verification error of approximate unlearning for SGD. From this analysis, we first derive an easy-to-compute proxy for verification error (termed unlearning error). The analysis also informs the design of a new training objective penalty that limits the overall change in weights during SGD and as a result facilitates approximate unlearning with lower verification error. We validate our theoretical work through an empirical evaluation on CIFAR-10, CIFAR-100, and IMDB sentiment analysis.