 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpaired Photo-to-Caricature Translation on Faces in the Wild
Paper and Code

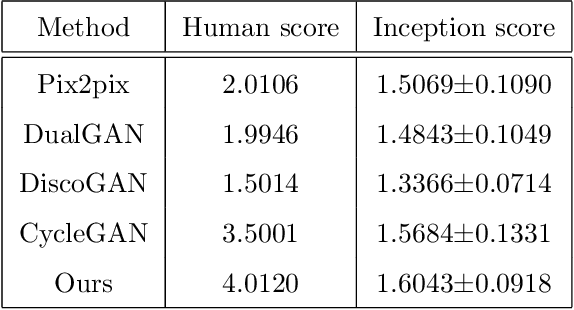
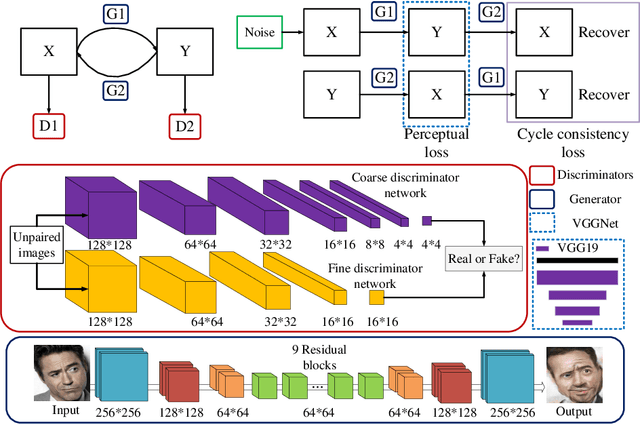
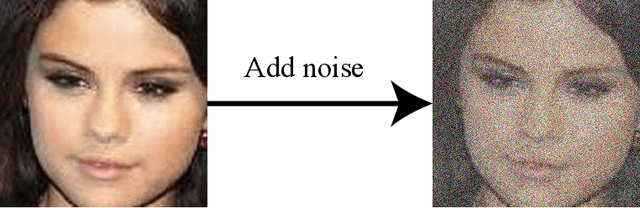
Recently, image-to-image translation has been made much progress owing to the success of conditional Generative Adversarial Networks (cGANs). And some unpaired methods based on cycle consistency loss such as DualGAN, CycleGAN and DiscoGAN are really popular. However, it's still very challenging for translation tasks with the requirement of high-level visual information conversion, such as photo-to-caricature translation that requires satire, exaggeration, lifelikeness and artistry. We present an approach for learning to translate faces in the wild from the source photo domain to the target caricature domain with different styles, which can also be used for other high-level image-to-image translation tasks. In order to capture global structure with local statistics while translation, we design a dual pathway model with one coarse discriminator and one fine discriminator. For generator, we provide one extra perceptual loss in association with adversarial loss and cycle consistency loss to achieve representation learning for two different domains. Also the style can be learned by the auxiliary noise input. Experiments on photo-to-caricature translation of faces in the wild show considerable performance gain of our proposed method over state-of-the-art translation methods as well as its potential real applications.