 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Dependency Parsing from Scratch
Paper and Code
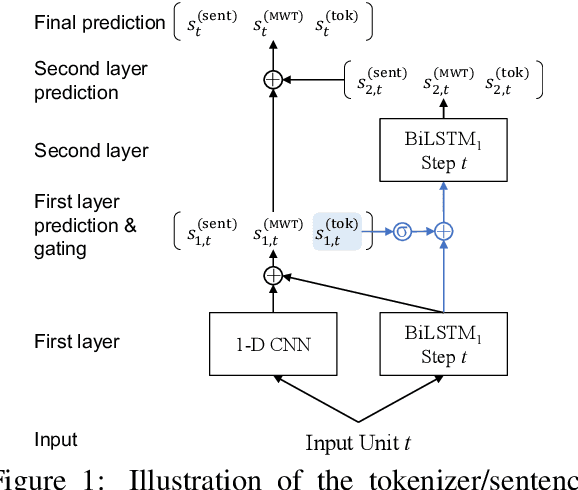
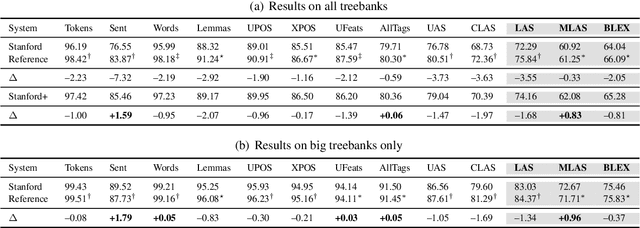
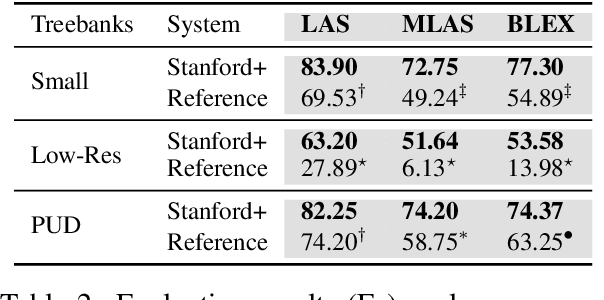
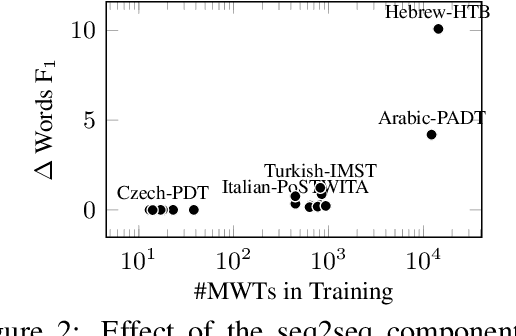
This paper describes Stanford's system at the CoNLL 2018 UD Shared Task. We introduce a complete neural pipeline system that takes raw text as input, and performs all tasks required by the shared task, ranging from tokenization and sentence segmentation, to POS tagging and dependency parsing. Our single system submission achieved very competitive performance on big treebanks. Moreover, after fixing an unfortunate bug, our corrected system would have placed the 2nd, 1st, and 3rd on the official evaluation metrics LAS,MLAS, and BLEX, and would have outperformed all submission systems on low-resource treebank categories on all metrics by a large margin. We further show the effectiveness of different model components through extensive ablation studies.