 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnintended Effects on Adaptive Learning Rate for Training Neural Network with Output Scale Change
Paper and Code
Mar 05, 2021


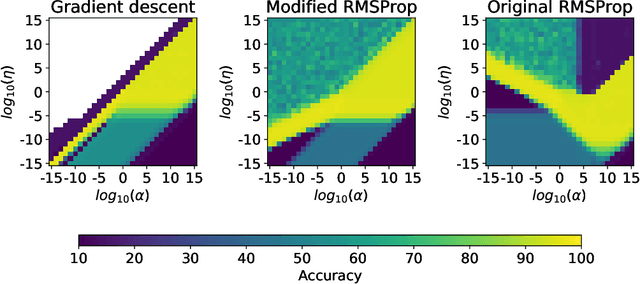
A multiplicative constant scaling factor is often applied to the model output to adjust the dynamics of neural network parameters. This has been used as one of the key interventions in an empirical study of lazy and active behavior. However, we show that the combination of such scaling and a commonly used adaptive learning rate optimizer strongly affects the training behavior of the neural network. This is problematic as it can cause \emph{unintended behavior} of neural networks, resulting in the misinterpretation of experimental results. Specifically, for some scaling settings, the effect of the adaptive learning rate disappears or is strongly influenced by the scaling factor. To avoid the unintended effect, we present a modification of an optimization algorithm and demonstrate remarkable differences between adaptive learning rate optimization and simple gradient descent, especially with a small ($<1.0$) scaling factor.