 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniNet: Unified Architecture Search with Convolution, Transformer, and MLP
Paper and Code
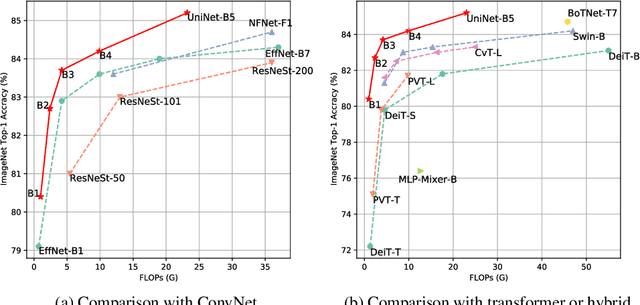
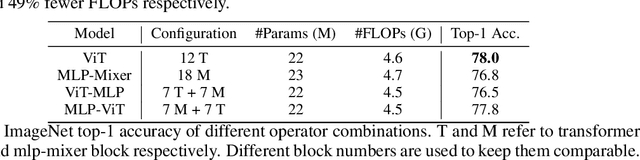

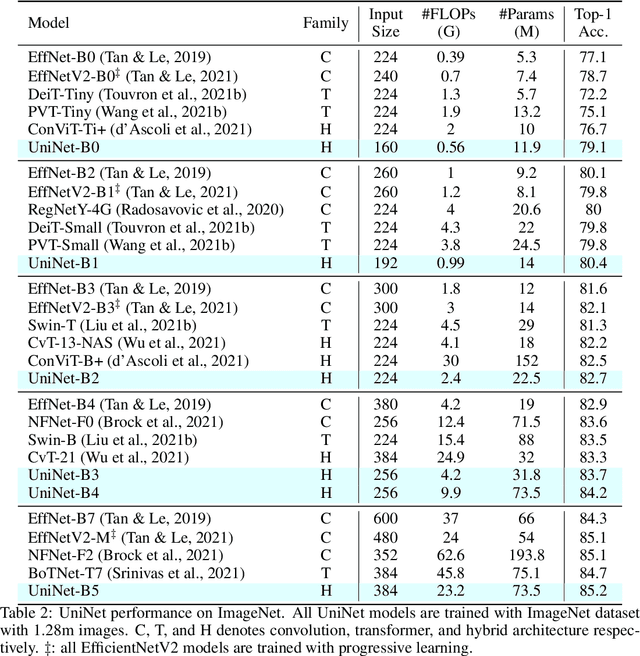
Recently, transformer and multi-layer perceptron (MLP) architectures have achieved impressive results on various vision tasks. However, how to effectively combine those operators to form high-performance hybrid visual architectures still remains a challenge. In this work, we study the learnable combination of convolution, transformer, and MLP by proposing a novel unified architecture search approach. Our approach contains two key designs to achieve the search for high-performance networks. First, we model the very different searchable operators in a unified form, and thus enable the operators to be characterized with the same set of configuration parameters. In this way, the overall search space size is significantly reduced, and the total search cost becomes affordable. Second, we propose context-aware downsampling modules (DSMs) to mitigate the gap between the different types of operators. Our proposed DSMs are able to better adapt features from different types of operators, which is important for identifying high-performance hybrid architectures. Finally, we integrate configurable operators and DSMs into a unified search space and search with a Reinforcement Learning-based search algorithm to fully explore the optimal combination of the operators. To this end, we search a baseline network and scale it up to obtain a family of models, named UniNets, which achieve much better accuracy and efficiency than previous ConvNets and Transformers. In particular, our UniNet-B5 achieves 84.9% top-1 accuracy on ImageNet, outperforming EfficientNet-B7 and BoTNet-T7 with 44% and 55% fewer FLOPs respectively. By pretraining on the ImageNet-21K, our UniNet-B6 achieves 87.4%, outperforming Swin-L with 51% fewer FLOPs and 41% fewer parameters. Code is available at https://github.com/Sense-X/UniNet.